
① 算法简介
朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法,属于贝叶斯分类器中的模型之一,依靠已知类别的数据集对模型进行训练,以此实现对新类别数据的识别与分类,多用于文本分类,例如谣言的识别以及侮辱性语句的识别
② 理论基础
朴素贝叶斯预测的理论基础为贝叶斯决策论(Bayesian decision theory)
其独辟蹊径,利用样本特征概率来预测分类
朴素贝叶斯的核心部分即为贝叶斯法则,而贝叶斯法则的基础是条件概率
贝叶斯法则: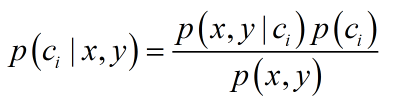
其中C表示类别,x,y代表标签向量,以侮辱性文本识别为例,C0表示无侮辱性文本,C1表示存在侮辱性文本,假设在100份样本中存在10份侮辱性文本,则P(C1)=0.1
那么我们应该如何求P(x,y|C1)呢,在这个公式中x,y是多维的,因为一个侮辱性文本中往往并非只有单一的侮辱性词汇
而我们假设x为出现次数,y为出现种类,便可以得出类似于P(次数=2,种类=1|C1)=probability的式子,在这里我们假设x的特征之间是相互独立的(y同理),相互之间不存在影响,这便是朴素贝 叶斯中的朴素二字的由来。在特征之间相互独立的情况下,我们易得 P(x,y|C)=P(x1,y1|C)P(x2,y2|C)…*P(xn,yn|C)
若要进行文本分类,训练集应由正常性的文档以及侮辱性文档组成,以此反映侮辱性文档中的侮辱性词汇出现的频率,想要统计出现频率,需要利用词集模型及词袋模型
词集模型
对于给定文档,只统计某个侮辱性词汇(准确说是词条)是否在本文档出现
词袋模型
对于给定文档,统计某个侮辱性词汇在本文当中出现的频率,除此之外,往往还需要剔除重要性极低的高频词和停用词。因此,词袋模型更精炼,也更有效。
需要解释的是,为了高效计算,求解P(x,y|C)时是向量化操作的,因此不会一个个的求解P(xn,yn|C)
③数据处理
以文档分类为例,为了获取足够多的模型,需要将文本拆分识别
若是采用词集模型,只需要检索文档中是否出现过某词汇,而不需要考虑该词汇出现的频率
若是采用词袋模型,应考虑某一文本中单词出现的频率来构建文本向量,即文本向量表示该文本中某词汇出现的次数,而不像前面仅表示词汇是否出现在文本中,最后将其统计为词典,囊括所有训练集中所有必要词汇,排除无用高配词汇的干扰
最后统计出现的词汇总个数,用出现的特殊词汇除以词汇总个数,即可得到相应的条件概率
将新文档的条件概率与模型中的进行对比,就可以判断新文档是否是侮辱性文档
④总结&后话
朴素贝叶斯作为一种基于概率的分类方法,其应用是十分广泛的,并且大多数情况下分类预测效果较好,例如垃圾邮件过滤等
但其也有着局限性,朴素贝叶斯假设特征之间完全相互独立,但是现实情况下这种假设难以成立
总体上来说,朴素贝叶斯原理和实现都比较简单,学习和预测的效率都很高,是一种经典而常用的分类算法
Comments NOTHING