
原文/对照翻译
Abstract 摘要
In image retrieval, deep local features learned in a data-driven manner have been demonstrated effective to improve retrieval performance. To realize efficient retrieval on large image database, some approaches quantize deep local features with a large codebook and match images with aggregated match kernel. However, the complexity of these approaches is nontrivial with large memory footprint, which limits their capability to jointly perform feature learning and aggregation.
在图像检索中,以数据驱动的方式学习深度局部特征可以有效地提高检索性能。为了实现对大型图像数据库的高效检索,一些方法使用大码本量化深度局部特征,使用聚合匹配核进行图像匹配。然而,这些方法的复杂性和巨大的内存占用限制了它们联合执行特征学习和聚合的能力。
To generate compact global representations while maintaining regional matching capability, we propose a unified framework to jointly learn local feature representation and aggregation. In our framework, we first extract deep local features using CNNs. Then, we design a tokenizer module to aggregate them into a few visual tokens, each corresponding to a specific visual pattern. This helps to remove background noise, and capture more discriminative regions in the image. Next, a refinement block is introduced to enhance the visual tokens with self-attention and cross-attention. Finally, different visual tokens are concatenated to generate a compact global representation. The whole framework is trained end-to-end with image-level labels. Extensive experiments are conducted to evaluate our approach, which outperforms the state-of-theart methods on the Revisited Oxford and Paris datasets. Our code is available at https://github.com/MCC-WH/Token.
为了在保持区域匹配能力的同时生成紧凑的全局表示,我们提出了一个统一的框架来共同学习局部特征表示和聚合。在我们的框架中,我们首先使用cnn提取深度局部特征。然后,我们设计了一个标记器模块,将它们聚合成几个视觉标记,每个标记对应于一个特定的视觉模式。这有助于去除背景噪声,并在图像中捕获更多的判别区域。其次,引入了一个细化块,通过自关注和交叉关注来增强视觉标记。最后,将不同的视觉标记连接起来以生成紧凑的全局表示。整个框架使用图像级标签进行端到端训练。我们进行了大量的实验来评估我们的方法,该方法在Revisited Oxford和Paris数据集上优于最先进的方法。我们的代码可在https://github.com/MCC-WH/Token上获得。
Introduction 介绍
Given a large image corpus, image retrieval aims to efficiently find target images similar to a given query. It is challenging due to various situations observed in large-scale dataset, e.g., occlusions, background clutter, and dramatic viewpoint changes. In this task, image representation, which describes the content of images to measure their similarities, plays a crucial role. With the introduction of deep learning into computer vision, significant progress has been witnessed in learning image representation for image retrieval in a data-driven paradigm. Generally, there are two main types of representation for image retrieval. One is global feature, which maps an image to a compact vector, while the other is local feature, where an image is described with hundreds of short vectors
给定一个大的图像语料库,图像检索的目的是有效地找到与给定查询相似的目标图像。由于在大规模数据集中观察到的各种情况,例如遮挡,背景杂波和戏剧性的视点变化,这是具有挑战性的。在这项任务中,描述图像内容以衡量其相似性的图像表示起着至关重要的作用。随着深度学习引入计算机视觉,在数据驱动范式中学习图像表示用于图像检索方面取得了重大进展。通常,图像检索有两种主要的表示类型。一种是全局特征,将图像映射到压缩向量;另一种是局部特征,用数百个短向量描述图像。

Query image is on the left (black outline) with a target object (orange box), and the right are the top-ranking images for the query. Our approach achieves similar results as HOW, which use large visual codebook to aggregate local features, with lower memory and latency. Green solid outline: positive images for the query; red solid outline: negative results.
图1:不同方法的前5名检索结果,包括DELG (Cao, Araujo, and Sim 2020), SOLAR (Ng et al2020), HOW (Tolias, Jenicek, and Chum 2020)和我们的方法。
查询图像位于左侧(黑色轮廓),带有目标对象(橙色框),右侧是该查询的排名靠前的图像。我们的方法获得了与HOW相似的结果,HOW使用大型视觉码本来聚合本地特征,具有更低的内存和延迟。绿色实线轮廓:正面图像用于查询;红色实线:阴性结果。
In global feature based image retrieval, although the representation is compact, it usually lacks capability to retrieve target images with only partial match. As shown in Fig.1(a) and (b), when the query image occupies only a small region in the target images, global features tend to return false positive examples, which are somewhat similar but do not indicate the same instance as the query image.
在基于全局特征的图像检索中,虽然表示是紧凑的,但它通常缺乏检索只有部分匹配的目标图像的能力。如图1(a)和(b)所示,当查询图像在目标图像中只占很小的区域时,全局特征倾向于返回假阳性样例,这些假阳性样例与查询图像有些相似,但并不表示相同的实例。
Recently, many studies have demonstrated the effectiveness of combining deep local features with traditional ASMK aggregation method in dealing with background clutter and occlusion. In those approaches, the framework usually consists of two stages: feature extraction and feature aggregation, where the former extracts discriminative local features, which are further aggregated by the latter for the efficient retrieval.
最近,许多研究已经证明了结合深层局部特征的有效性,采用传统的ASMK聚集方法处理背景杂波和遮挡。在这些方法中,框架通常包括两个阶段:特征提取和特征聚合,前者提取有区别的局部特征,后者将其进一步聚合以实现高效检索。
However, they require offline clustering and coding procedures, which lead to a considerable complexity of the whole framework with a high memory footprint and long retrieval latency. Besides, it is difficult to jointly learn local features and aggregation due to the involvement of large visual codebook and hard assignment in quantization.
然而,它们需要离线聚类和编码过程,这导致整个框架相当复杂,内存占用大,检索延迟长。此外,由于涉及大量的视觉码本和量化分配困难,局部特征和聚合难以共同学习。
Some existing works such as NetVLAD try to learn local features and aggregation simultaneously. They aggregate the feature maps output by CNNs into compact global features with a learnable VLAD layer.
Specifically, they discard the original features and adopt the sum of residual vectors of each visual word as the representation of an image. However, considering the large variation and diversity of content in different images, these visual words are too coarse-grained for the features of a particular image. This leads to insufficient discriminative capability of the residual vectors, which further hinders the performance of the aggregated image representation.
现有的一些作品,如NetVLAD,尝试同时学习局部特征和聚合。他们将cnn输出的特征映射聚合成具有可学习VLAD层的紧凑全局特征。
具体来说,它们抛弃原始特征,采用每个视觉词的残差向量之和作为图像的表示。然而,考虑到不同图像中内容的巨大变化和多样性,这些视觉词对于特定图像的特征来说过于粗粒度。这导致残差向量的判别能力不足,进一步影响了聚合图像表示的性能。
To address the above issues, we propose a unified framework to jointly learn and aggregate deep local features. We treat the feature map output by CNNs as original deep local features. To obtain compact image representations while preserving the regional matching capability, we propose a tokenizer to adaptively divide the local features into groups with spatial attention. These local features are further aggregated to form the corresponding visual tokens. Intuitively, the attention mechanism ensures that each visual token corresponds to some visual pattern and these patterns are aligned across images. Furthermore, a refinement block is introduced to enhance the obtained visual tokens with selfattention and cross-attention. Finally, the updated attention maps are used to aggregate original local features for enhancing the existing visual tokens. The whole framework is trained end-to-end with only image-level labels.
为了解决上述问题,我们提出了一个统一的框架来共同学习和聚合深度局部特征。我们将cnn输出的特征映射作为原始的深度局部特征。为了在保持区域匹配能力的同时获得紧凑的图像表示,我们提出了一种标记器来自适应地将局部特征划分为具有空间关注的组。这些局部特征进一步聚合形成相应的视觉标记。直觉上,注意力机制确保每个视觉标记对应于一些视觉模式,这些模式在图像中对齐。在此基础上,引入了一个细化块,通过自关注和交叉关注对得到的视觉标记进行增强。最后,利用更新后的注意力图对原有的局部特征进行聚合,增强已有的视觉标记。整个框架只使用图像级标签进行端到端训练。
Compared with the previous methods, there are two advantages in our approach. First, by expressing an image with a few visual tokens, each corresponding to some visual pattern, we implicitly achieve local pattern alignment with the aggregated global representation. As shown in Fig. 1 (d), our approach performs well in the presence of background clutter and occlusion. Secondly, the global representation obtained by aggregation is compact with a small memory footprint. These facilitate effective and efficient semantic content matching between images. We conduct comprehensive experiments on the Revisited Oxford and Paris datasets, which are further mixed with one million distractors. Ablation studies demonstrate the effectiveness of the tokenizer and the refinement block. Our approach surpasses the stateof-the-art methods by a considerable margin.
与以前的方法相比,我们的方法有两个优点。首先,通过使用几个视觉标记来表达图像,每个标记对应一些视觉模式,我们隐式地实现了与聚合全局表示的局部模式对齐。如图1 (d)所示,我们的方法在存在背景杂波和遮挡的情况下表现良好。其次,聚合得到的全局表示紧凑,占用内存小。这些有助于图像之间有效和高效的语义内容匹配。我们在重新访问的牛津和巴黎数据集上进行了全面的实验,这些数据集进一步混合了100万个干扰物。烧蚀实验证明了标记器和细化块的有效性。我们的方法大大超过了最先进的方法。
Related Work 相关工作
In this section, we briefly review the related work including local feature and global feature based image retrieval.
Local feature. Traditionally local features are extracted using hand-crafted detectors and descriptors. They are first organized in bag-of-words and further enhanced by spatial validation , hamming embedding and query expansion . Recently, tremendous advances have been made to learn local features suitable for image retrieval in a data-driven manner. Among these approaches, the state-of-the-art approach is HOW , which uses attention learning to distinguish deep local features with imagelevel annotations. During testing, it combines the obtained local features with the traditional ASMK aggregation method. However, HOW cannot jointly learn feature representation and aggregation due to the very large codebook and the hard assignment during the quantization process. Moreover, its complexity is considerable with a high memory footprint. Our method uses a few visual tokens to effectively represent image. The feature representation and aggregation are jointly learned.
在本节中,我们简要回顾了基于局部特征和全局特征的图像检索的相关工作。
局部特征。传统的局部特征提取是使用手工制作的检测器和描述符。它们首先以词袋的形式进行组织,然后通过空间验证、汉明嵌入和查询扩展进一步增强。近年来,在以数据驱动的方式学习适合图像检索的局部特征方面取得了巨大进展。在这些方法中,最先进的方法是HOW,它使用注意学习来区分深度局部特征和图像级注释。在测试过程中,将获得的局部特征与传统的ASMK聚合方法相结合。然而,由于码本非常大,且量化过程中分配困难,HOW无法同时学习特征表示和聚合。此外,它的复杂性相当高,内存占用也很大。我们的方法使用一些视觉标记来有效地表示图像。特征表示和聚合是联合学习的。
Global feature. Compact global features reduce memory footprint and expedite the retrieval process. They simplify image retrieval to a nearest neighbor search and extend the previous query expansion to an efficient exploration of the entire nearest neighbor graph of the dataset by diffusion. Before deep learning, they are mainly developed by aggregating hand-crafted local features, e.g., VLAD, Fisher vectors ASMK . Recently, global features are obtained simply by performing the pooling operation on the feature map of CNNs. Many pooling methods have been explored,e.g.,max-pooling, sumpooling, weightedsum-pooling, regional-max-pooling, generalized mean-pooling , and so on. These networks are trained using ranking or classification losses. Differently, our method tokenizes the feature map into several visual tokens, enhances the visual tokens using the refinement block, concatenates different visual tokens and performs dimension reduction. Through these steps, our method generates a compact global representation while maintaining the regional matching capability
全局特征。紧凑的全局特性减少了内存占用并加快了检索过程。它们将图像检索简化为最近邻搜索,并将以前的查询扩展扩展为通过扩散对数据集的整个最近邻图进行有效的探索。在深度学习之前,它们主要是通过聚合手工制作的局部特征来开发的,例如VLAD, Fisher vectors ASMK。目前,对cnn的特征映射进行池化操作即可获得全局特征。已经探索了许多池化方法,例如;、max-pooling、sumpooling、weighting-sum-pooling、region-max-pooling、generalized mean-pooling等。这些网络使用排序或分类损失进行训练。不同的是,我们的方法将特征映射标记为多个视觉标记,使用细化块增强视觉标记,连接不同的视觉标记并执行降维。通过这些步骤,我们的方法在保持区域匹配能力的同时生成紧凑的全局表示。
Methodology 方法
An overview of our framework is shown in Fig. 2. Given an image, we first obtain the original deep local featuresthrough a CNN backbone. These local features are obtained with limited receptive fields covering part of the input image. Thus, we follow to apply the Local Feature Self-Attention (LFSA) operation on to obtain context-aware local features . Next, we divide them into L groups with spatial attention mechanism, and the local features of each group are aggregated to form a visual token . We denote the set of obtained visual tokens as.
Furthermore, we introduce a refinement block to update the obtained visual tokens based on the previous local features . Finally, all the visual tokens are concatenated and we reduce its dimension to form the final global descriptor. ArcFace margin loss is used to train the whole network.
我们的框架概述如图2所示。给定图像,我们首先通过CNN主干获得原始的深度局部特征。这些局部特征是通过覆盖部分输入图像的有限接受域获得的。因此,我们遵循应用局部特征自关注(LFSA)操作来获得上下文感知的局部特征。接下来,我们利用空间注意机制将它们划分为L组,并将每组的局部特征聚合成一个视觉标记。我们将得到视觉标记集表示。
此外,我们还引入了一个细化块来更新基于先前局部特征的可视化标记。最后,将所有可视标记连接起来,我们将其降维以形成最终的全局描述符。利用ArcFace边际损失对整个网络进行训练。
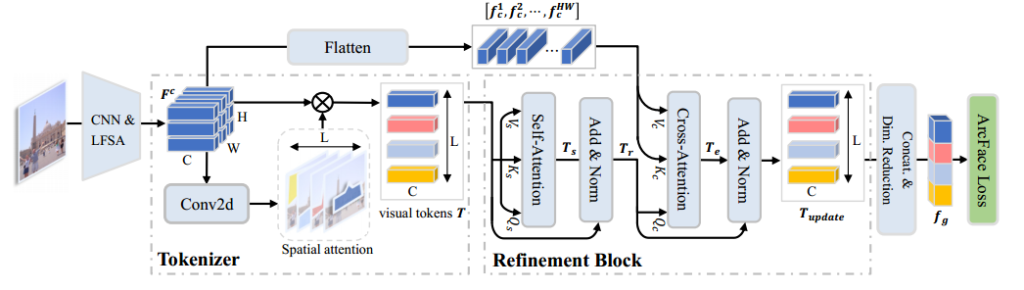
图2:我们框架的概述。给定图像,我们首先使用CNN和局部特征自关注(LFSA)模块提取局部特征F。然后,它们被标记为L个具有空间注意力的视觉标记。在此基础上,引入了一个细化块,通过自关注和交叉关注来增强所获得的视觉标记。最后,我们将所有的视觉标记连接起来,形成一个紧凑的全局表示fg并降低其维数。
Tokenizer 编译器
To effectively cope with the challenging conditions observed in large datasets, such as noisy backgrounds, occlusions, etc., image representation is expected to find patch-level matches between images. A typical pipeline to tackle these challenges consists of local descriptor extraction, quantization with a large visual codebook created usually by kmeans and descriptor aggregation into a single embedding.
However, due to the offline clustering and hard assignment of local features, it is difficult to optimize feature learning and aggregation simultaneously, which further limits the discriminative power of the image representation.
To alleviate this problem, we here use spatial attention to extract the desired visual tokens. By training, the attention module can adaptively discover discriminative visual patterns.
为了有效应对在大数据集中观察到的具有挑战性的条件,如嘈杂的背景、遮挡等,图像表示期望找到图像之间的补丁级匹配。解决这些挑战的典型方法包括局部描述符提取、使用通常由kmeans创建的大型可视化代码本进行量化以及将描述符聚合到单个嵌入中。
然而,由于离线聚类和局部特征的难分配,难以同时优化特征学习和聚合,进一步限制了图像表示的判别能力。
为了缓解这个问题,我们在这里使用空间注意力来提取所需的视觉标记。通过训练,注意模块可以自适应地发现判别性的视觉模式。
施工中
Experiments 实验
Experimental 实验设置
Training dataset. The clean version of Google landmarks dataset V2 (GLDv2-clean) (Weyand et al 2020) is used fortraining. It is first collected by Google and further cleaned by researchers from the Google Landmark Retrieval Competition 2019. It contains a total of 1,580,470 images and 81,313 classes. We randomly divide it into two subsets ‘train’=‘val’ with 80%=20% split. The ‘train’ split is used for training model, and the ‘val’ split is used for validation.
训练数据集。使用Google地标数据集V2的clean版本(GLDv2-clean) (Weyand et al 2020)进行训练。它首先由谷歌收集,并由2019年谷歌地标检索大赛的研究人员进一步清理。它总共包含1,580,470个图像和81,313个类。我们随机将其分成两个子集' train ' = ' val ', 80%=20%分割。' train '分割用于训练模型,' val '分割用于验证。

表1:mAP与完整基准测试中现有方法的比较。下划线:最好的以前的方法。黑色加粗:效果最好。
Evaluation datasets and metrics. Revisited versions of the original Oxford5k (Philbin et al 2007) and Paris6k (Philbin et al 2008) datasets are used to evaluate our method, which are denoted as ROxf and RPar (Radenovic et al 2018) in ´ the following. Both datasets contain 70 query images and additionally include 4,993 and 6,322 database images, respectively. Mean Average Precision (mAP) is used as our evaluation metric on both datasets with Medium and Hard protocols. Large-scale results are further reported with the R1M dataset, which contains one million distractor images
评估数据集和指标。使用原始Oxford5k (Philbin等人2007年)和Paris6k (Philbin等人2008年)数据集的重新访问版本来评估我们的方法,它们在下文中被标记为ROxf和RPar (Radenovic等人2018年)。两个数据集分别包含70张查询图像和4,993张和6,322张数据库图像。平均平均精度(mAP)被用作我们对中、硬协议数据集的评估指标。使用R1M数据集进一步报告了大规模结果,该数据集包含100万张分心图像。
Training details. All models are pre-trained on ImageNet.
For image augmentation, a 512 × 512-pixel crop is taken from a randomly resized image and then undergoes random color jittering. We use a batch size of 128 to train our model on 4 NVIDIA RTX 3090 GPUs for 30 epochs, which takes about 3 days. SGD is used to optimize the model, with an initial learning rate of 0.01, a weight decay of 0.0001, and a momentum of 0.9. A linearly decaying scheduler is adopted to gradually decay the learning rate to 0 when the desired number of steps is reached. The dimension d of the global feature is set as 1024. For the ArcFace margin loss, we empirically set the margin m as 0.2 and the scale γ as 32:0. Refinement block number N is set to 2. Test images are resized with the larger dimension equal to 1024 pixels, preserving the aspect ratio. Multiple scales are adopted, i.e. L2 normalization is applied for each scale independently, then three global features are averagepooled, followed by another L2 normalization. We train each model 5 times and evaluate the one with median performance on the validation set.
训练细节。所有模型都在ImageNet上进行预训练。
对于图像增强,从随机调整大小的图像中截取512 × 512像素的裁剪,然后进行随机的颜色抖动。我们使用128个批处理大小在4个NVIDIA RTX 3090 gpu上训练我们的模型30个epoch,大约需要3天。使用SGD对模型进行优化,初始学习率为0.01,权重衰减为0.0001,动量为0.9。采用线性衰减调度器,当达到所需步数时,将学习率逐渐衰减到0。全局特征的维数d设置为1024。对于ArcFace边缘损失,我们经验地将边缘m设置为0.2,尺度γ设置为32:0。细化块号N设为2。测试图像被调整为较大的尺寸为1024像素,保持长宽比。采用多尺度,即对每个尺度分别进行L2归一化,然后对三个全局特征进行平均,再进行L2归一化。我们训练每个模型5次,并评估在验证集上具有中位数性能的模型。
Results on Image Retrieval 图像检索结果
Setting for fair comparison. Commonly, existing methods are compared under different settings, e.g., training set,backbone network, feature dimension, loss function, etc.
This may affect our judgment on the effectiveness of the proposed method. In Tab. 1, we re-train several methods under the same settings (using GLDv2-clean dataset and ArcFace loss, 2048 global feature dimension, ResNet101 as backbone), marked with y. Based on this benchmark, we fairly compare the mAP performance of various methods and ours.
设置公平比较。通常,现有方法在不同的设置下进行比较,如训练集、骨干网、特征维数、损失函数等。
这可能会影响我们对所建议方法有效性的判断。在表1中,我们在相同的设置下重新训练了几种方法(使用GLDv2-clean数据集和ArcFace loss, 2048全局特征维数,ResNet101作为主干),用y标记。基于这个基准,我们公平地比较了各种方法和我们的mAP性能。
Comparison with the state of the art. Tab. 1 compares our approach extensively with the state-of-the-art retrieval methods. Our method achieves the best mAP performance in all settings. We divide the previous methods into three groups:
(1) Local feature aggregation. The current state-of-the-art local aggregation method is R101-HOW. We outperform it in mAP by 1:86% and 4:06% on the ROxf dataset and by 3:91%, and 7:80% on the RPar dataset with Medium and Hard protocols, respectively. For R1M, we also achieve the best performance. The results show that our aggregation method is better than existing local feature aggregation methods based on large visual codebook.
(2) Global single-pass. When trained with GLDv2-clean, R101-DELG achieves the best performance mostly. When using ResNet101 as the backbone, the comparison between our method and it in mAP is 82:28% vs. 78:24%, 66:57% vs. 60:15% on the ROxf dataset and 89:34% vs. 88:21%, 78:56% vs. 76:15% on the RPar dataset with Medium and Hard protocols, respectively. These results well demonstrate the superiority of our framework.
(3) Global feature followed by local feature re-ranking. We outperform the best two-stage method (R101-DELG+SP) in mAP by 0:50%, 1:80% on the ROxf dataset and 0:88%, 1:76% on the RPar datasets with Medium and Hard protocols, respectively. Although 2-stage solutions well promote their single-stage counterparts, our method that aggregates local features into a compact descriptor is a better option.
与技术水平的比较。表1将我们的方法与最先进的检索方法进行了广泛的比较。我们的方法在所有设置下都实现了最佳的mAP性能。我们将前面的方法分为三大类:
(1)局部特征聚合。当前最先进的局部聚合方法是R101-HOW。在ROxf数据集上,我们在mAP上的表现分别为1:86%和4:06%,在RPar数据集上,我们在Medium和Hard协议上的表现分别为3:91%和7:80%。对于R1M,我们也达到了最好的性能。结果表明,该方法优于现有的基于大型视觉码本的局部特征聚合方法。
(2)全局单通。当使用GLDv2-clean进行训练时,R101-DELG大多能达到最佳性能。当使用ResNet101作为主干时,我们的方法与mAP中的方法在ROxf数据集上的比较分别为82:28% vs. 78:24%, 66:57% vs. 60:15%,在RPar数据集上的比较分别为89:34% vs. 88:21%, 78:56% vs. 76:15%。这些结果很好地证明了我们的框架的优越性。
(3)全局特征,局部特征重新排序。在ROxf数据集和RPar数据集上,我们分别比mAP中最佳的两阶段方法(R101-DELG+SP)高出0:50%、1:80%和0:88%、1:76%。虽然两阶段解决方案可以很好地促进单阶段解决方案,但我们将局部特征聚合到紧凑描述符中的方法是更好的选择。
Qualitative results. To explore what the proposed tokenizer learned, we visualize the spatial attention generated by the cross-attention layer of the last refinement block in the Fig. 3 (a). Although there is no direct supervision, different visual tokens are associated with different visual patterns. Most of these patterns focus on the foreground building and remain consistent across images, which implicitly enable pattern alignment. e.g., the 3rd visual token reflects the semantics of “the upper edge of the window”.
To further analyze how visual tokens improve the performance, we select the top-2 results of the “hertford” query from the ROxf dataset for the case study. As shown in Fig. 1, when the query object only occupies a small part of the target image, the state-of-the-art methods with global features return false positives which are semantically similar to the query. Our approach uses visual tokens to distinguish different visual patterns, which has the capability of regional matching. In Fig. 3 (b), the 2nd visual token corresponds to the visual pattern described by the query image.
定性的结果。为了探索所提出的标记器学习了什么,我们将图3 (a)中最后一个细化块的交叉注意层生成的空间注意可视化。尽管没有直接监督,但不同的视觉标记与不同的视觉模式相关联。这些模式中的大多数都关注前景构建,并在图像之间保持一致,从而隐式地支持模式对齐。例如,第三个视觉标记反映了“窗口的上边缘”的语义。
为了进一步分析可视化标记如何提高性能,我们从ROxf数据集中选择“hertford”查询的前2个结果进行案例研究。如图1所示,当查询对象仅占目标图像的一小部分时,具有全局特征的最先进方法返回与查询语义相似的假阳性。该方法利用视觉标记来区分不同的视觉模式,具有区域匹配的能力。在图3 (b)中,第二个视觉标记对应于查询图像所描述的视觉模式。
Speed and memory costs. In Tab. 2, we report retrieval latency, feature extraction latency and memory footprint on R1M for different methods. Compared to the local feature aggregation approaches, most of the global features have a smaller memory footprint. To perform spatial verification,“R101-DELG+SP” needs to store a large number of local features, and thus requires about 485 GB of memory. Our method uses a small number of visual tokens to represent the image, generating a 1024-dimensional global feature with a memory footprint of 3.9 GB. We further compress the memory requirements of global features with PQ quantization . As shown in Tab. 1 ´ and Tab. 2, the compressed features greatly reduce the memory footprint with only a small performance loss. Among these methods, our method appears to be a good solution in the performance-memory trade-off
速度和内存成本。在表2中,我们报告了不同方法在R1M上的检索延迟、特征提取延迟和内存占用。与局部特征聚合方法相比,大多数全局特征占用的内存更小。为了进行空间验证,“R101-DELG+SP”需要存储大量的本地特征,因此需要大约485 GB的内存。我们的方法使用少量的视觉标记来表示图像,生成一个1024维的全局特征,内存占用为3.9 GB。我们利用PQ量化进一步压缩全局特征的内存需求。如表1和表2所示,压缩后的特性极大地减少了内存占用,而性能损失很小。在这些方法中,我们的方法似乎是性能-内存权衡的一个很好的解决方案
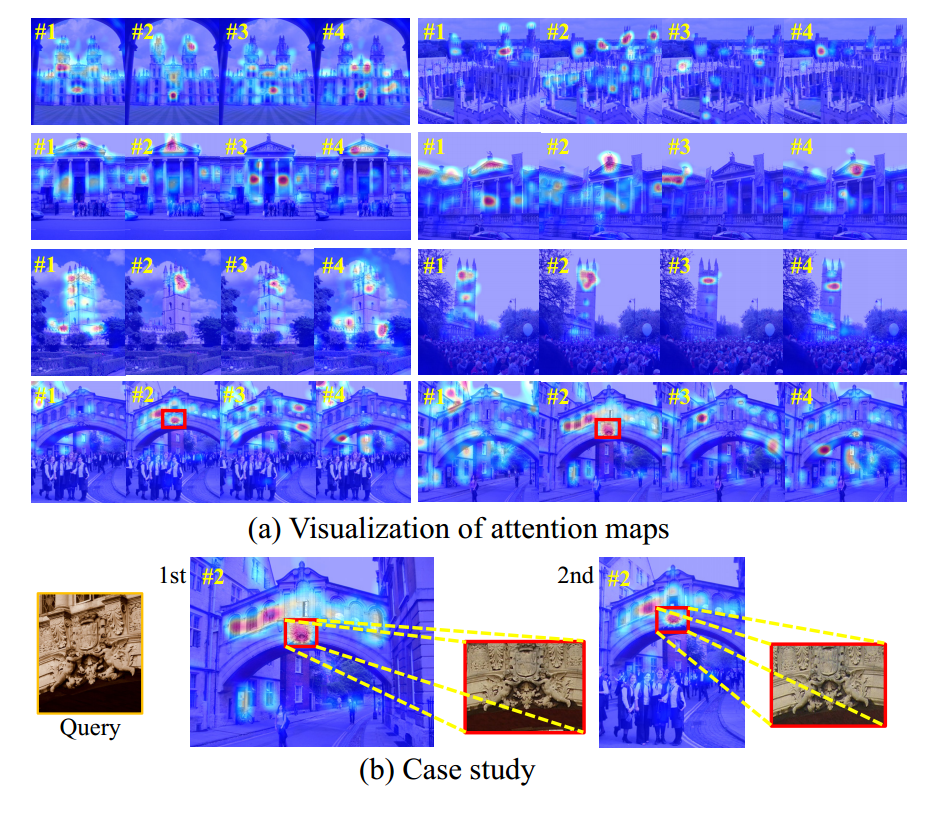
图3:定性的例子。(a)与八幅图像的不同视觉标记有关的注意图的可视化。#i表示第i个视觉标记。(b) ROxf数据集中“hertford”查询的前2个检索结果的详细分析。第二个视觉标记关注目标图像中查询图像的内容,该图像用红色框起。
The extraction of global features is faster, since the extraction of local features usually requires scaling the image to seven scales, while global features generally use three scales. Our aggregation method requires tokenization and iterative enhancement, which is slightly slower than direct spatial pooling, e.g., 125 ms for ours vs. 109 ms for “R101DELG”. The average retrieval latency of our method on R1M is 0.2871 seconds, which demonstrates the potential of our method for real-time image retrieval.
全局特征的提取速度更快,因为局部特征的提取通常需要将图像缩放到7个尺度,而全局特征通常使用3个尺度。我们的聚合方法需要标记化和迭代增强,这比直接空间池稍微慢一些,例如,我们的方法是125 ms,而“R101DELG”是109 ms。我们的方法在R1M上的平均检索延迟为0.2871秒,这证明了我们的方法在实时图像检索方面的潜力。
Ablation Study 消融实验
Verification of different components. In Tab. 3, we provide experimental results to validate the contribution of the three components in our framework, by adding individual components to the baseline framework. When the tokenizer is adopted, there is a significant improvement in overall performance. mAP increases from 77:0% to 79:8% on ROxfMedium and 56:0% to 62:5% on ROxf-Hard. This indicates that dividing local features into groups according to visual patterns is more effective than direct global spatial pooling. From the 3rd and last row, the performance is further enhanced when the refinement block is introduced, which shows that enhancing the visual tokens with the original features further makes them more discriminative. There is also a performance improvement when the Local Feature SelfAttention (LFSA) is incorporated.
不同部件的验证。在表3中,我们提供了实验结果,通过将单个组件添加到基线框架中,来验证框架中三个组件的贡献。当采用标记器时,总体性能会有显著提高。ROxfMedium的mAP从77:0%增加到79:8%,ROxf-Hard的mAP从56:0%增加到62:5%。这表明根据视觉模式将局部特征分组比直接的全局空间池化更有效。从第三行和最后一行开始,当引入细化块时,性能进一步提高,这表明使用原始特征进一步增强视觉标记使其更具区别性。当加入本地特征自关注(LFSA)时,性能也有所提高。
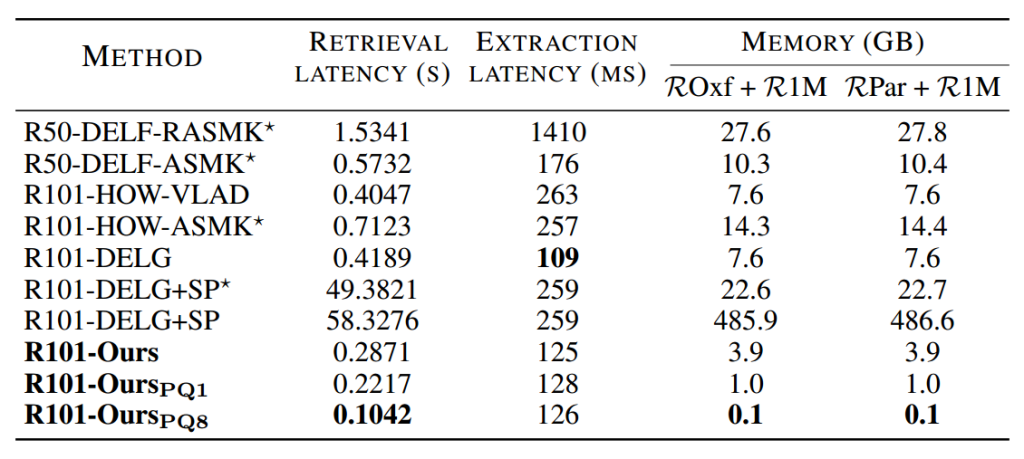
表2:时间和内存度量。我们报告了单线程GPU (RTX 3090) / CPU (Intel Xeon CPU E5-2640 v4 @ 2.40GHz)的提取时间和ROxf+R1M数据库的搜索时间(在单线程CPU上)。

表3:不同成分的消融研究。我们使用R101-SPoC作为基准,并逐步添加标记器,局部特征自关注(LFSA)和细化块。
Impact of each component in the refinement block. The role of the different components in the refinement block is shown in Tab. 4. By removing the individual components, we find that modeling the relationship between different visual words before and further enhancing the visual tokens using the original local features demonstrate the effectiveness in enhancing the aggregated features.
细化块中每个组件的影响。表4显示了细化块中不同组件的角色。通过去除单个成分,我们发现在之前对不同视觉词之间的关系进行建模,并使用原始的局部特征进一步增强视觉标记,可以有效地增强聚合特征。

表4:细化块中组件的分析。
Impact of tokenizer type. In Tab. 5, we compare our Attenbased tokenizer with the other two tokenizers: (1) Vq-Based.We directly define visual tokens as a matrix .It is randomly initialized and further updated by a moving average operation in one mini-batch. See the appendix for details. (2) Learned. It is similar to the Vq-Based method, except that T is set as the network parameters, learned during training. Our method achieves the best performance. We use the attention mechanism to generate visual tokens directly from the original local features. Compared with the other two, our approach obtains more discriminative visual tokens with a better capability to match different images.
Impact of token number. The granularity of visual tokens is influenced by their number. As shown in Tab. 6, as L increases, mAP performance first increases and then decreases, achieving the best at L = 4. This is due to the lack of capability to distinguish local features when the number of visual tokens is small; conversely, when the number is large, they are more fine-grained and noise may be introduced when grouping local features.
标记器类型的影响。在表5中,我们将基于注意力的标记器与其他两个标记器进行比较:(1)基于vq的标记器。我们直接将视觉标记定义为一个矩阵,它是随机初始化的,并通过移动平均操作在一个小批量中进一步更新。详见附录。(2)学习。它与基于vq的方法类似,不同之处在于将T设置为网络参数,在训练过程中学习。我们的方法达到了最好的性能。我们使用注意机制直接从原始的局部特征生成视觉标记。与其他两种方法相比,我们的方法获得了更多的判别性视觉标记,具有更好的图像匹配能力。
令牌数量的影响。视觉标记的粒度受其数量的影响。如表6所示,随着L的增大,mAP性能先增大后减小,在L = 4时达到最佳。这是因为当视觉标记的数量很少时,缺乏区分局部特征的能力;相反,当数量大时,它们的粒度更细,在对局部特征进行分组时可能会引入噪声。
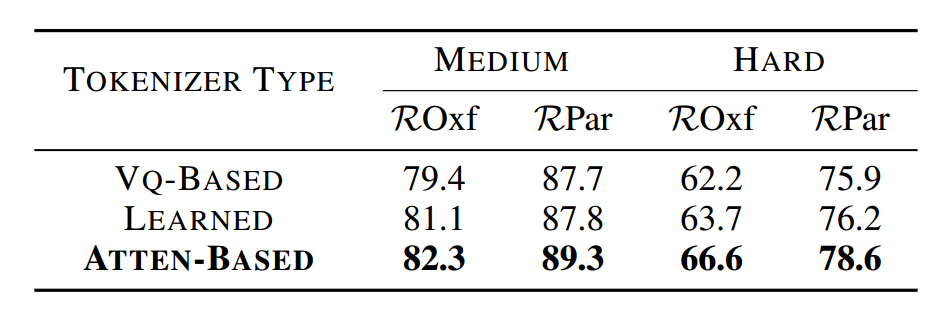
表5:标记器不同变体的mAP比较。

Table 6: mAP comparison of visual tokens number L.
表6:视觉标记数L的mAP比较。
Conclusion 结论
In this paper, we propose a joint local feature learning and aggregation framework, which generates compact global representations for images while preserving the capability of regional matching. It consists of a tokenizer and a refinement block. The former represents the image with a few visual tokens, which is further enhanced by the latter based on the original local features. By training with image-level labels, our method produces representative aggregated features. Extensive experiments demonstrate that the proposed method achieves superior performance on image retrieval benchmark datasets. In the future, we will extend the proposed aggregation method to a variety of existing local features, which means that instead of directly performing local feature learning and aggregation end-to-end, local features of images are first extracted using existing methods and further aggregated with our method.Acknowledgements. This work was supported in part by the National Key R&D Program of China under contract 2018YFB1402605, in part by the National Natural Science Foundation of China under Contract 62102128, 61822208 and 62172381, and in part by the Youth Innovation Promotion Association CAS under Grant 2018497. It was also supported by the GPU cluster built by MCC Lab of Information Science and Technology Institution, USTC.
在本文中,我们提出了一个局部特征学习和聚合的联合框架,该框架在保留区域匹配能力的同时,为图像生成紧凑的全局表示。它由一个标记器和一个细化块组成。前者用一些视觉标记来表示图像,后者在原有局部特征的基础上进一步增强图像。通过使用图像级标签进行训练,我们的方法产生具有代表性的聚合特征。大量的实验表明,该方法在图像检索基准数据集上取得了优异的性能。在未来,我们将把提出的聚合方法扩展到各种现有的局部特征,这意味着不是直接进行局部特征学习和端到端聚合,而是首先使用现有的方法提取图像的局部特征,然后用我们的方法进一步聚合。国家重点科技发展计划项目(项目编号:2018YFB1402605),国家自然科学基金项目(项目编号:62102128、61822208、62172381),中国科学院青年创新促进会项目(项目编号:2018497)并得到了中国科学技术大学信息科学技术学院MCC实验室构建的GPU集群的支持。
省流总结版
对于大的图像语料库,进行图像检索是具有挑战性的,而图像检索大致有两种主要的表示类型,一种是全局特征,将图像映射到压缩向量;另一种是局部特征,用数百个短向量描述图像。
而全局特征一般会缺乏检索只有部分匹配的图像的能力,容易返回假阳性样例。
对于深层局部特征来说,他们需要离线聚类和编码过程,导致框架复杂,性能占用大。
为了解决上述问题,提出了一个统一的框架来共同学习和聚合深度局部特征。我们将CNN输出的特征映射作为原始的深度局部特征。为了在保持区域匹配能力的同时获得紧凑的图像表示,我们提出了一种标记器来自适应地将局部特征划分为具有空间关注的组。这些局部特征进一步聚合形成相应的视觉标记。直觉上,注意力机制确保每个视觉标记对应于一些视觉模式,这些模式在图像中对齐。在此基础上,引入了一个细化块,通过自关注和交叉关注对得到的视觉标记进行增强。最后,利用更新后的注意力图对原有的局部特征进行聚合,增强已有的视觉标记。整个框架只使用图像级标签进行端到端训练。
我们的框架概述如图所示。给定图像,我们首先通过CNN主干获得原始的深度局部特征。这些局部特征是通过覆盖部分输入图像的有限接受域获得的。因此,我们遵循应用局部特征自关注(LFSA)操作来获得上下文感知的局部特征。接下来,我们利用空间注意机制将它们划分为L组,并将每组的局部特征聚合成一个视觉标记。我们将得到视觉标记集表示。
在此基础上,引入了一个细化块,通过自关注和交叉关注来增强所获得的视觉标记。最后,我们将所有的视觉标记连接起来,形成一个紧凑的全局表示fg并降低其维数,我们将其降维以形成最终的全局描述符。利用ArcFace边际损失对整个网络进行训练。

Comments NOTHING