
对照翻译
Abstract 摘要
Image retrieval is the problem of searching an image database for items that are similar to a query image. To address this task, two main types of image representations have been studied: global and local image features. In this work, our key contribution is to unify global and local features into a single deep model, enabling accurate retrieval with efficient feature extraction. We refer to the new model as DELG, standing for DEep Local and Global features. We leverage lessons from recent feature learning work and propose a model that combines generalized mean pooling for global features and attentive selection for local features. The entire network can be learned end-to-end by carefully balancing the gradient flow between two heads – requiring only image-level labels. We also introduce an autoencoder-based dimensionality reduction technique for local features, which is integrated into the model, improving training efficiency and matching performance.
Comprehensive experiments show that our model achieves state-of-the-art image retrieval on the Revisited Oxford and Paris datasets, and state-of-the-art singlemodel instance-level recognition on the Google Landmarks dataset v2. Code and models are available at https://github.com/tensorflow/models/ tree/master/research/delf
图像检索是在图像数据库中搜索与查询图像相似的项的问题。为了解决这个问题,我们研究了两种主要的图像表示类型:全局和局部图像特征。在这项工作中,我们的关键贡献是将全局和局部特征统一到单个深度模型中,从而通过有效的特征提取实现准确的检索。我们将新模型称为DELG,代表深度局部和全局特征。我们利用最近的特征学习工作的经验教训,提出了一个结合全局特征的广义均值池和局部特征的细心选择的模型。通过仔细平衡两个头部之间的梯度流,整个网络可以端到端学习——只需要图像级标签。我们还引入了一种基于自编码器的局部特征降维技术,将其集成到模型中,提高了训练效率和匹配性能。
综合实验表明,我们的模型在Revisited Oxford和Paris数据集上实现了最先进的图像检索,在Google Landmarks数据集v2上实现了最先进的单模型实例级识别。代码和模型可在https://github.com/tensorflow/models/ tree/master/research/delf获得
Introduction 介绍
Large-scale image retrieval is a long-standing problem in computer vision, which saw promising results even before deep learning revolutionized the field. Central to this problem are the representations used to describe images and their similarities.
Two types of image representations are necessary for high image retrieval performance: global and local features. A global feature, also commonly referred to as “global descriptor” or “embedding”, summarizes the contents of an image, often leading to a compact representation; information about spatial arrangement of visual elements is lost. Local features , on the other hand, comprise descriptors and geometry information about specific image regions; they are especially useful to match images depicting rigid objects. Generally speaking, global features are better at recall, while local features are better at precision.
大规模图像检索是计算机视觉领域一个长期存在的问题,甚至在深度学习彻底改变该领域之前,它就已经取得了可喜的成果。这个问题的核心是用来描述图像及其相似性的表示。
高图像检索性能需要两种类型的图像表示:全局特征和局部特征。全局特征,通常也被称为“全局描述符”或“嵌入”,概括了图像的内容,通常导致紧凑的表示;视觉元素的空间排列信息丢失。另一方面,局部特征包括关于特定图像区域的描述符和几何信息;它们在匹配描绘刚性物体的图像时特别有用。一般来说,全局特征在查全率上更好,而局部特征在查准率上更好。
Global features can learn similarity across very different poses where local features would not be able to find correspondences; in contrast, the score provided by local feature-based geometric verification usually reflects image similarity well, being more reliable than global feature distance.
A common retrieval system setup is to first search by global features, then re-rank the top database images using local feature matching – to get the best of both worlds. Such a hybrid approach gained popularity in visual localization and instance-level recognition problems.
全局特征可以在非常不同的姿势中学习相似性,而局部特征无法找到对应;相比之下,基于局部特征的几何验证提供的分数通常能很好地反映图像的相似度,比全局特征距离更可靠。
一种常见的检索系统设置是首先通过全局特征进行搜索,然后使用局部特征匹配对顶级数据库图像进行重新排序——以获得两全其美的效果。这种混合方法在视觉定位和实例级识别问题中得到了广泛的应用。
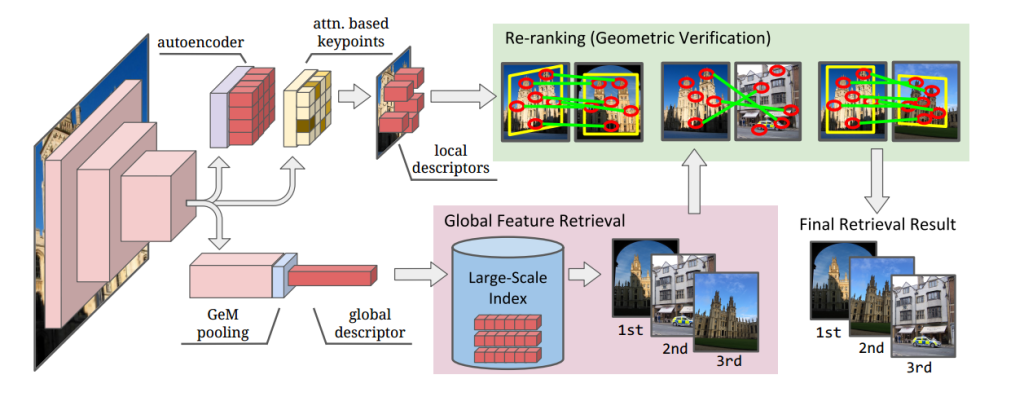
图1:我们提出的DELG (DEep Local and Global features)模型(左)联合提取深度局部和全局特征。全局特征可以在检索系统的第一阶段使用,以有效地选择最相似的图像(下图)。然后可以使用局部特征来重新排列顶级结果(右上),从而提高系统的精度。统一模型利用卷积神经网络诱导的分层表示来学习局部和全局特征,并结合全局池化和细心的局部特征检测的最新进展。
Today, most systems that rely on both these types of features need to separately extract each of them, using different models. This is undesirable since it may lead to high memory usage and increased latency, e.g., if both models require specialized and limited hardware such as GPUs. Besides, in many cases similar types of computation are performed for both, resulting in redundant processing and unnecessary complexity.
今天,大多数依赖这两种类型特征的系统需要使用不同的模型分别提取它们中的每一个。这是不可取的,因为它可能导致高内存使用和增加延迟,例如,如果两个模型都需要专门的和有限的硬件,如gpu。此外,在许多情况下,对两者执行类似类型的计算,导致冗余处理和不必要的复杂性。
Contributions. (1) Our first contribution is a unified model to represent both local and global features, using a convolutional neural network (CNN), referred to as DELG (DEep Local and Global features) – illustrated in Fig. 1. This allows for efficient inference by extracting an image’s global feature, detected keypoints and local descriptors within a single model. Our model is enabled by leveraging hierarchical image representations that arise in CNNs , which we couple to generalized mean pooling and attentive local feature detection . (2) Second, we adopt a convolutional autoencoder module that can successfully learn low-dimensional local descriptors. This can be readily integrated into the unified model, and avoids the need of post-processing learning steps, such as PCA, that are commonly used. (3) Finally, we design a procedure that enables end-toend training of the proposed model using only image-level supervision. This requires carefully controlling the gradient flow between the global and local network heads during backpropagation, to avoid disrupting the desired representations. Through systematic experiments, we show that our joint model achieves state-of-the-art performance on the Revisited Oxford, Revisited Paris and Google Landmarks v2 datasets.
贡献。(1)我们的第一个贡献是一个统一的模型来表示局部和全局特征,使用卷积神经网络(CNN),称为DELG(深度局部和全局特征)-如图1所示。这允许通过在单个模型中提取图像的全局特征、检测到的关键点和局部描述符来进行有效的推理。我们的模型是通过利用cnn中出现的分层图像表示来实现的,我们将其与广义均值池化和细心的局部特征检测相结合。(2)其次,我们采用卷积自编码器模块,可以成功学习低维局部描述符。这可以很容易地集成到统一模型中,并且避免了通常使用的后处理学习步骤,例如PCA。(3)最后,我们设计了一个程序,使所提出的模型只使用图像级监督进行端到端训练。这需要在反向传播期间仔细控制全局和本地网络头之间的梯度流,以避免破坏所需的表示。通过系统实验,我们表明我们的联合模型在Revisited Oxford、Revisited Paris和Google Landmarks v2数据集上实现了最先进的性能。
Related Work 相关工作
We review relevant work in local and global features, focusing mainly on approaches related to image retrieval.
Local features. Hand-crafted techniques such as SIFT and SURF have been widely used for retrieval problems. Early systems worked by searching for query local descriptors against a large database of local descriptors, followed by geometrically verifying database images with sufficient number of correspondences.
Bag-of-Words and related methods followed, by relying on visual words obtained via local descriptor clustering, coupled to TF-IDF scoring. The key advantage of local features over global ones for retrieval is the ability to perform spatial matching, often employing RANSAC. This has been widely used, as it produces reliable and interpretable scores. Recently, several deep learning-based local features have been proposed. The one most related to our work is DELF; our proposed unified model incorporates DELF’s attention module, but with a much simpler training pipeline, besides also enabling global feature extraction.
Global features excel at delivering high image retrieval performance with compact representations. Before deep learning was popular in computer vision, they were developed mainly by aggregating hand-crafted local descriptors. Today, most high-performing global features are based on deep convolutional neural networks, which are trained with ranking-based or classification losses. Our work leverages recent learned lessons in global feature design, by adopting GeM pooling and ArcFace loss. This leads to improved global feature retrieval performance compared to previous techniques, which is further boosted by geometric re-ranking with local features obtained from the same model.
Joint local and global CNN features. Previous work considered neural networks for joint extraction of global and local features. For indoor localization, Taira et al used NetVLAD to extract global features for candidate pose retrieval, followed by dense local feature matching using feature maps from the same network. Simeoni et al’s DSM detected keypoints in activation maps from global feature models using MSER; activation channels are interpreted as visual words, in order to propose correspondences between a pair of images. Our work differs substantially from, since they only post-process pre-trained global feature models to produce local features, while we jointly train local and global. Sarlin et al distill pre-trained local and global features into a single model, targeting localization applications. In contrast, our model is trained end-to-end for image retrieval, and is not limited to mimicking separate pre-trained local and global models. To the best of our knowledge, ours is the first work to learn a non-distilled model producing both local and global features.
Dimensionality reduction for image retrieval. PCA and whitening are widely used for dimensionality reduction of local and global features in image retrieval.
As discussed in, whitening downweights co-occurences of local features, which is generally beneficial for retrieval applications. Mukundan et al further introduce a shrinkage parameter that controls the extent of applied whitening. If supervision in the form of matching pairs or category labels is available, more sophisticated methods can be used. More recently, Gordo et al propose to replace PCA/whitening by a fully-connected layer, that is learned together with the global descriptor.
我们回顾了局部和全局特征方面的相关工作,主要关注与图像检索相关的方法。
当地的特色。手工制作的技术,如SIFT和SURF已广泛用于检索问题。早期系统的工作方式是,在一个庞大的局部描述符数据库中搜索查询局部描述符,然后用足够数量的对应对数据库图像进行几何验证。
随后采用Bag-of-Words及相关方法,依靠通过局部描述符聚类获得的视觉词,结合TF-IDF评分。在检索方面,局部特征比全局特征的关键优势是能够执行空间匹配,通常使用RANSAC。这已经被广泛使用,因为它产生可靠和可解释的分数。近年来,人们提出了几种基于深度学习的局部特征。与我们的工作最相关的是DELF;我们提出的统一模型结合了DELF的注意力模块,但具有更简单的训练管道,此外还支持全局特征提取。
全局特征擅长于用紧凑的表示提供高图像检索性能。在深度学习在计算机视觉中流行之前,它们主要是通过聚合手工制作的局部描述符来开发的。今天,大多数高性能的全局特征都是基于深度卷积神经网络的,它是用基于排名或分类损失的方法训练的。通过采用GeM池和ArcFace loss,我们的工作利用了最近在全局特征设计中吸取的经验教训。与以前的技术相比,这可以提高全局特征检索性能,并通过从同一模型中获得的局部特征进行几何重新排序进一步提高全局特征检索性能。
CNN本地和全球联合专题。以前的工作考虑神经网络联合提取全局和局部特征。对于室内定位,Taira等人使用NetVLAD提取全局特征用于候选姿态检索,然后使用来自同一网络的特征映射进行密集的局部特征匹配。Simeoni等人的DSM利用MSER从全局特征模型中检测激活图中的关键点;激活通道被解释为视觉词,以提出一对图像之间的对应关系。我们的工作与此有很大的不同,因为他们只是对预训练的全局特征模型进行后处理来产生局部特征,而我们是联合训练局部和全局特征的。Sarlin等人将预先训练好的局部和全局特征提取到一个单一的模型中,以定位应用为目标。相比之下,我们的模型是端到端的图像检索训练,并不局限于模拟单独的预训练的局部和全局模型。据我们所知,我们是第一个学习产生局部和全局特征的非蒸馏模型的工作。
图像检索的降维方法。在图像检索中,PCA和白化被广泛用于局部和全局特征的降维。
如前所述,白化降低了局部特征的共现性,这通常有利于检索应用。Mukundan等人进一步引入了一个收缩参数来控制应用美白的程度。如果以配对对或类别标签的形式进行监督,则可以使用更复杂的方法。最近,Gordo等人提出用一个与全局描述符一起学习的全连接层取代PCA/白化。
In this paper, our goal is to compose a system that can be learned end-to-end, using only image-level labels and without requiring post-processing stages that make training more complex. Also, since we extract local features from feature maps of common CNN backbones, they tend to be very high-dimensional and infeasible for large-scale problems.
All above-mentioned approaches would either require a separate post-processing step to reduce the dimensionality of features, or supervision at the level of local patches – making them unsuitable to our needs. We thus introduce an autoencoder in our model, which can be jointly and efficiently learned with the rest of the network. It requires no extra supervision as it can be trained with a reconstruction loss.
在本文中,我们的目标是构建一个可以端到端学习的系统,仅使用图像级标签,不需要使训练更复杂的后处理阶段。此外,由于我们是从常见的CNN主干的特征图中提取局部特征,它们往往是非常高维的,对于大规模问题是不可行的。
上述所有方法要么需要单独的后处理步骤来降低特征的维数,要么需要在局部补丁级别进行监督——这使得它们不适合我们的需求。因此,我们在模型中引入了一个自动编码器,它可以与网络的其余部分共同有效地学习。它不需要额外的监督,因为它可以接受重建损失的训练。
DELG
Design considerations 设计注意事项
For optimal performance, image retrieval requires semantic understanding of the types of objects that a user may be interested in, such that the system can distinguish between relevant objects versus clutter/background. Both local and global features should thus focus only on the most discriminative information within the image. However, there are substantial differences in terms of the desired behavior for these two feature modalities, posing a considerable challenge to jointly learn them.
Global features should be similar for images depicting the same object of interest, and dissimilar otherwise. This requires high-level, abstract representations that are invariant to viewpoint and photometric transformations. Local features, on the other hand, need to encode representations that are grounded to specific image regions; in particular, the keypoint detector should be equivariant with respect to viewpoint, and the keypoint descriptor needs to encode localized visual information. This is crucial to enable geometric consistency checks between query and database images, which are widely used in image retrieval systems.
Besides, our goal is to design a model that can be learned end-to-end, with local and global features, without requiring additional learning stages. This simplifies the training pipeline, allowing faster iterations and wider applicability. In comparison, it is common for previous feature learning work to require several learning stages: attentive deep local feature learning requires 3 learning stages (fine-tuning, attention, PCA); deep global features usually require two stages, e.g., region proposal and Siamese training, or Siamese training and supervised whitening, or ranking loss training and PCA.
为了获得最佳性能,图像检索需要对用户可能感兴趣的对象类型进行语义理解,以便系统能够区分相关对象与杂乱/背景。因此,局部和全局特征都应该只关注图像中最具区别性的信息。然而,这两种特征模态在期望行为方面存在很大差异,这给联合学习它们带来了相当大的挑战。
对于描绘相同感兴趣对象的图像,全局特征应该是相似的,而在其他情况下则不同。这需要对视点和光度变换保持不变的高级抽象表示。另一方面,局部特征需要编码基于特定图像区域的表示;关键点检测器对于视点应该是等变的,关键点描述符需要编码局部化的视觉信息。这对于实现查询图像和数据库图像之间的几何一致性检查至关重要,这在图像检索系统中被广泛使用。
此外,我们的目标是设计一个可以端到端学习的模型,具有局部和全局特征,而不需要额外的学习阶段。这简化了训练管道,允许更快的迭代和更广泛的适用性。相比之下,之前的特征学习工作通常需要几个学习阶段:细心的深度局部特征学习需要3个学习阶段(微调、注意、PCA);深度全局特征通常需要两个阶段,例如区域建议和暹罗训练,或者暹罗训练和监督白化,或者排序损失训练和PCA。
Model 模型
略
Training 训练
We propose to train the model using only image-level labels, as illustrated in Fig. 2. In particular, note that we do not require patch-level supervision to train local features, unlike most recent works.
Besides the challenge to acquire the annotations, note that patch-level supervision could help selecting repeatable features, but not necessarily the discriminative ones; in contrast, our model discovers discriminative features by learning which can distinguish the different classes, given by image-level labels. In this weakly-supervised local feature setting, it is very important to control the gradient flow between the global and local feature learning, which is discussed in more detail below.
我们建议只使用图像级标签来训练模型,如图2所示。特别要注意的是,我们不需要补丁级监督来训练局部特征,这与最近的大多数作品不同。
除了获取注释的挑战之外,请注意补丁级监督可以帮助选择可重复的特征,但不一定是判别性的特征;相比之下,我们的模型通过学习发现判别特征,这些特征可以区分图像级别标签给出的不同类别。在这种弱监督的局部特征设置中,控制全局和局部特征学习之间的梯度流是非常重要的,下面将详细讨论。
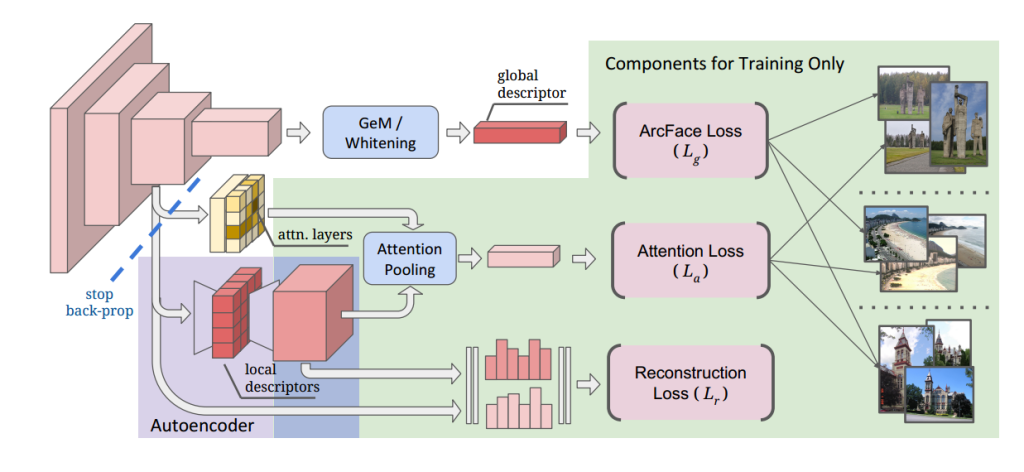
图2:我们的训练管道示意图。绿色突出显示的组件仅在训练期间使用。有两种分类损失:ArcFace用于全局特征学习(Lg), softmax用于注意学习(La)。在这两种情况下,分类目标都是区分不同的地标(一个实例级识别问题)。用重构损失(Lr)进一步训练自编码器(紫色)。整个模型是端到端学习的,并且从阻止从La和Lr到CNN主干的梯度反向传播中受益匪浅。
Global features. For global feature learning, we adopt a suitable loss function with L2-normalized classifier weights ^W, followed by scaled softmax normalization and cross-entropy loss; this is sometimes referred to as “cosine classifier”. Additionally, we adopt the ArcFace margin , which has shown excellent results for global feature learning by inducing smaller intra-class variance. Concretely, given g^, we first compute the cosine similarity against ^W, adjusted by the ArcFace margin. The ArcFace-adjusted cosine similarity can be expressed as AF(u; c):
全局特征。对于全局特征学习,我们采用合适的l2归一化分类器权值^W的损失函数,其次是缩放softmax归一化和交叉熵损失;这有时被称为“余弦分类器”。此外,我们还采用了ArcFace margin,该方法通过诱导较小的类内方差,在全局特征学习方面取得了很好的效果。具体地说,给定g^,我们首先计算对^W的余弦相似度,由ArcFace边缘调整。arcface调整后的余弦相似度可以表示为AF(u,c):
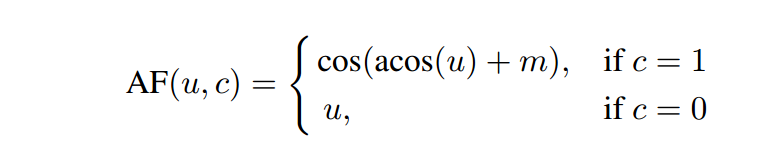
where u is the cosine similarity, m is the ArcFace margin and c is a binary value indicating if this is the ground-truth class. The cross-entropy loss, computed using softmax normalization can be expressed in this case as:
其中u是余弦相似度,m是ArcFace边距,c是一个二进制值,表示这是否是基真类。在这种情况下,使用softmax归一化计算的交叉熵损失可以表示为:
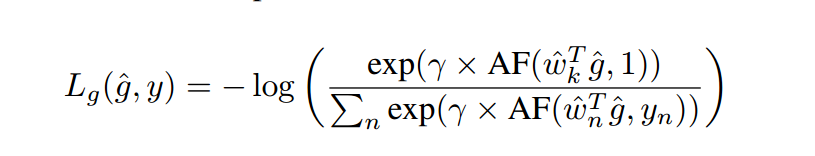
where γ is a learnable scalar, w^i refers to the L2-normalized classifier weights for class i, y is the one-hot label vector and k is the index of the ground-truth class (yk = 1).
其中γ为可学习标量,w^i为类i的l2归一化分类器权值,y为单热标签向量,k为基真类(yk = 1)的索引。
Local features. To train the local features, we use two losses. First, a mean-squared error regression loss that measures how well the autoencoder can reconstruct S. Denote S0 = T0(L) as the reconstructed version of S, with same dimensions, where T0 is a 1×1 convolutional layer with CS filters, followed by ReLU. The loss can be expressed as:
当地的特色。为了训练局部特征,我们使用了两个损失。首先,均方误差回归损失,测量自编码器重建S的效果。表示S0 = T0(L)作为S的重建版本,具有相同的维度,其中T0是带有CS滤波器的1×1卷积层,其次是ReLU。损失可以表示为:
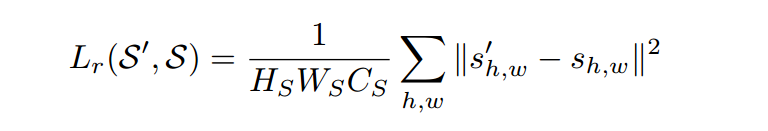
Second, a cross-entropy classification loss that incentivizes the attention module to select discriminative local features. This is done by first pooling the reconstructed features S 0 with attention weights ah;w:
其次,交叉熵分类损失激励注意力模块选择有区别的局部特征。这是通过首先将重构特征S0与注意权值ah,w池化来完成的:
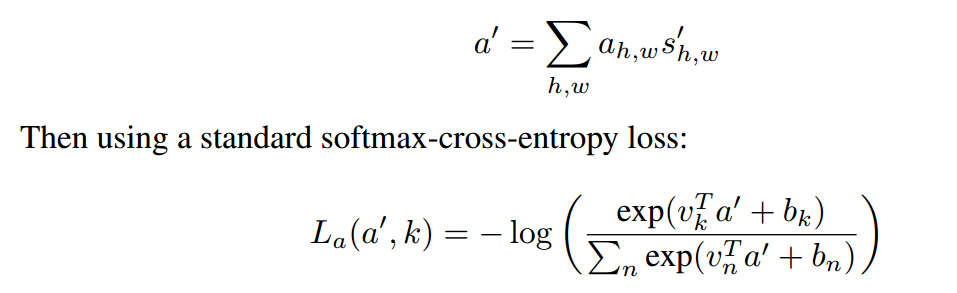
where vi ; bi refer to the classifier weights and biases for class i and k is the index of the ground-truth class; this tends to make the attention weights large for the discriminative features. The total loss is given by Lg + λLr + βLa.
其中vi;Bi为类I的分类器权值和偏置,k为基真类的指标;这往往会使判别特征的注意权重较大。总损耗为Lg + λLr + βLa。
Controlling gradients. Naively optimizing the above-mentioned total loss experimentally leads to suboptimal results, because the reconstruction and attention loss terms significantly disturb the hierarchical feature representation which is usually obtained when training deep models. In particular, both tend to induce the shallower features S to be more semantic and less localizable, which end up being sparser. Sparser features can more easily optimize Lr, and more semantic features may help optimizing La; this, as a result, leads to underperforming local features.
We avoid this issue by stopping gradient back-propagation from Lr and La to the network backbone, i.e., to S. This means that the network backbone is optimized solely based on Lg, and will tend to produce the desired hierarchical feature representation.
This is further discussed in the experimental section that follows.
控制梯度。在实验上天真地优化上述总损失会导致次优结果,因为重建和注意力损失项会严重干扰通常在训练深度模型时获得的分层特征表示。特别是,两者都倾向于使较浅的特征S更具语义性和更少的可本地化性,从而最终变得更稀疏。稀疏特征可以更容易地优化Lr,而更多的语义特征可能有助于优化La;因此,这将导致本地功能性能不佳。
我们通过停止从Lr和La到网络骨干的梯度反向传播来避免这个问题,即到s。这意味着网络骨干仅基于Lg进行优化,并且将倾向于产生所需的分层特征表示。
这将在接下来的实验部分中进一步讨论。
Experiments 实验
Experimental setup 实验设置
Model backbone and implementation. Our model is implemented using TensorFlow, leveraging the Slim model library.We use ResNet-50 (R50) and ResNet-101 (R101); R50 is used for ablation experiments. We obtain the shallower feature map S from the conv4 output, and the deeper feature map D from the conv5 output. Note that the Slim implementation moves the conv5 stride into the last unit from conv4, which we also adopt – helping reduce the spatial resolution of S. The number of channels in D is CD = 2048; GeM pooling is applied with parameter p = 3, which is not learned. The whitening fully-connected layer, applied after pooling, produces a global feature with dimensionality CF = 2048. The number of channels in S is CS = 1024; the autoencoder module learns a reduced dimensionality for this feature map with CT = 128. The attention network M follows the setup from, with 2 convolutional layers, without stride, using kernel sizes of 1; as activation functions, the first layer uses ReLU and the second uses Softplus.
模型主干和实现。我们的模型是使用TensorFlow实现的,利用Slim模型库。我们使用ResNet-50 (R50)和ResNet-101 (R101);R50用于烧蚀实验。我们从conv4的输出得到较浅的特征映射S,从conv5的输出得到较深的特征映射D。注意,Slim实现将conv5步幅从conv4移到最后一个单元,我们也采用了这一方法——帮助降低s的空间分辨率。D中的通道数CD = 2048;GeM池是用参数p = 3来应用的,这个参数不是学习得来的。泛白全连接层,池化后应用,得到一个全局特征,其维数CF = 2048。S中的通道数CS = 1024;自动编码器模块学习该特征映射的降维,CT = 128。注意网络M遵循以下设置:有2个卷积层,没有跨步,使用核大小为1;作为激活函数,第一层使用ReLU,第二层使用Softplus。
Training details. We use the training set of the Google Landmarks dataset (GLD) , containing 1:2M images from 15k landmarks, and divide it into two subsets ‘train’/‘val’ with 80%/20% split. The ‘train’ split is used for the actual learning, and the ‘val’ split is used for validating the learned classifier as training progresses. Models are initialized from pre-trained ImageNet weights. The images first undergo augmentation, by randomly cropping / distorting the aspect ratio; then, they are resized to 512 × 512 resolution. We use a batch size of 16, and train using 21 Tesla P100 GPUs asynchronously, for 1:5M steps (corresponding to approximately 25 epochs of the ‘train’ split). The model is optimized using SGD with momentum of 0:9, and a linearly decaying learning rate that reaches zero once the desired number of steps is reached. We experiment with initial learning rates within [3 × 10−4 ; 10−2 ] and report results for the best performing one. We set the ArcFace margin m = 0:1, the weight for La to β = 1, and the weight for Lr to λ = 10. The learnable scalar for the global loss Lg is initialized to γ = p CF = 45:25.
See also the appendices for results obtained when training models on GLDv2 .
训练细节。我们使用谷歌地标数据集(GLD)的训练集,包含来自15k个地标的1:20 m图像,并将其分为两个子集“train”/“val”,分割80%/20%。' train '分割用于实际学习,' val '分割用于在训练过程中验证学习到的分类器。模型从预训练的ImageNet权重初始化。图像首先通过随机裁剪/扭曲长宽比进行增强;然后,它们被调整为512 × 512分辨率。我们使用16个批处理大小,并使用21个Tesla P100 gpu异步训练,以1:5M的步骤(对应于“训练”分裂的大约25个epoch)。该模型使用动量为0:9的SGD进行优化,一旦达到所需的步数,线性衰减学习率就会达到零。我们实验的初始学习率在[3 × 10−4;10−2],并报告表现最佳的结果。我们设置ArcFace的边距m = 0:1, La的权重为β = 1, Lr的权重为λ = 10。全局损失Lg的可学习标量初始化为γ = p CF = 45:25。
关于在GLDv2上训练模型时获得的结果,请参见附录。
Evaluation datasets. To evaluate our model, we use several datasets. First, Oxford and Paris, with revisited annotations, referred to as ROxf and RPar, respectively. There are 4993 (6322) database images in the ROxf (RPar) dataset, and a different query set for each, both with 70 images. Performance is measured using mean average precision (mAP). Large-scale results are further reported with the R1M distractor set, which contains 1M images. As in previous papers, parameters are tuned in ROxf/RPar, then kept fixed for the large-scale experiments. Second, we report large-scale instance-level retrieval and recognition results on the Google Landmarks dataset v2 (GLDv2), using the latest ground-truth version (2:1). GLDv2-retrieval has 1129 queries (379 validation and 750 testing) and 762k database images; performance is measured using mAP@100. GLDv2-recognition has 118k test (41k validation and 77k testing) and 4M training images from 203k landmarks; the training images are only used to retrieve images and their scores/labels are used to form the class prediction; performance is measured using µAP@1. We perform minimal parameter tuning based on the validation split, and report results on the testing split.
评估数据集。为了评估我们的模型,我们使用了几个数据集。首先是Oxford和Paris,它们具有重新访问的注释,分别称为ROxf和RPar。ROxf (RPar)数据集中有4993(6322)个数据库图像,每个图像都有不同的查询集,都有70个图像。使用平均精度(mAP)来测量性能。使用包含1M图像的R1M分心物集进一步报道了大规模结果。与之前的论文一样,在ROxf/RPar中对参数进行了调整,然后在大规模实验中保持固定。其次,我们报告了在Google Landmarks数据集v2 (GLDv2)上使用最新的ground-truth版本(2:1)的大规模实例级检索和识别结果。gldv2检索有1129个查询(379个验证和750个测试)和762k个数据库图像;性能使用mAP@100进行测量。gldv2识别具有118k测试(41k验证和77k测试)和来自203k个地标的4M训练图像;训练图像仅用于检索图像,其分数/标签用于形成类别预测;使用µAP@1测量性能。我们基于验证分割执行最小的参数调优,并在测试分割上报告结果。
Feature extraction and matching. We follow the convention from previous work and use an image pyramid at inference time to produce multi-scale representations. For global features, we use 3 scales, L2 normalization is applied for each scale independently, then the three global features are average-pooled, followed by another L2 normalization step. For local features, we experiment with the same 3 scales, but also with the more expensive setting from using 7 image scales in total, with range from 0:25 to 2:0 (this latter setting is used unless otherwise noted). Local features are selected based on their attention scores A; a maximum of 1k local features are allowed, with a minimum attention score τ , where we set τ to the median attention score in the last iteration of training, unless otherwise noted. For local feature matching, we use RANSAC with an affine model. When re-ranking global feature retrieval results with local feature-based matching, the top 100 ranked images from the first stage are considered. For retrieval datasets, the final ranking is based on the number of inliers,then breaking ties using the global feature distance. For the recognition dataset, we
follow a similar protocol as to produce class predictions by aggregating scores of top retrieved images, where the scores of top images are given by min(i;70)70 + αc (here,i is the number of inliers, c the global descriptor cosine similarity and α = 0:25). Our focus is on improving image features for retrieval/recognition, so we do not consider techniques that post-process results such as query expansion or diffusion/graph traversal. These are expensive due to requiring additional passes over the database,but if desired could be integrated to our system and produce stronger performance.
特征提取与匹配。我们遵循以前工作的惯例,在推理时使用图像金字塔来产生多尺度表示。对于全局特征,我们使用3个尺度,对每个尺度分别进行L2归一化,然后对三个全局特征进行平均池化,再进行L2归一化步骤。对于局部特征,我们使用相同的3个比例进行实验,但也使用更昂贵的设置,总共使用7个图像比例,范围从0:25到2:0(除非另有说明,否则使用后一种设置)。根据注意力得分A来选择局部特征;最大允许有1k个局部特征,最小注意分数τ,其中我们将τ设置为最后一次训练迭代中的中位数注意分数,除非另有说明。对于局部特征匹配,我们使用带仿射模型的RANSAC。当使用基于局部特征的匹配对全局特征检索结果进行重新排序时,考虑第一阶段排名前100的图像。对于检索数据集,最终的排序是基于内联器的数量,然后使用全局特征距离打破联系。对于识别数据集,我们遵循类似的协议,通过聚合顶级检索图像的分数来产生类别预测,其中顶级图像的分数由min(i;70)70 + αc给出(这里,i是内线数,c是全局描述符余弦相似度,α = 0:25)。我们的重点是改进检索/识别的图像特征,因此我们不考虑后处理结果的技术,如查询扩展或扩散/图遍历。由于需要在数据库上进行额外的传递,这些方法的成本很高,但如果需要,可以集成到我们的系统,并产生更强的性能。
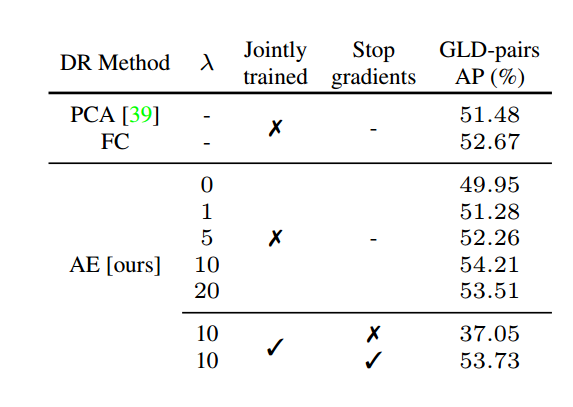
表1:局部特征消融。单独或联合训练的局部特征与不同降维方法的比较。我们报告了来自谷歌地标数据集(GLD)的匹配图像对的平均精度(AP)结果。
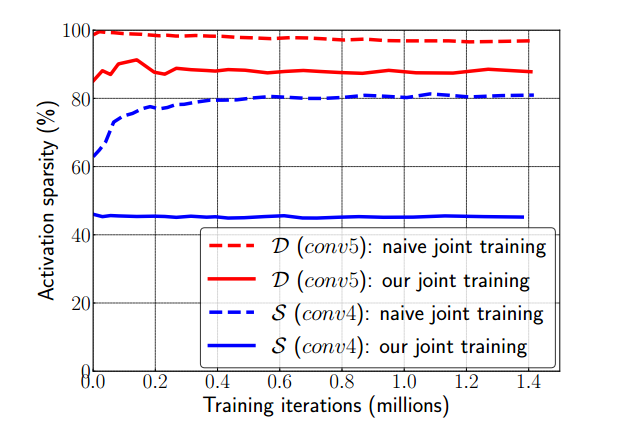
图3:D (conv5)和S (conv4)的激活稀疏度在训练迭代上的演化,比较了朴素联合训练方法和我们控制梯度传播的改进版本。朴素的方法导致更稀疏的特征映射。
Results 结果
First, we present ablation experiments, to compare features produced by our joint model against their counterparts which are separately trained, and also to discuss the effect of controlling the gradient propagation. For a fair comparison, our jointly trained features are evaluated against equivalent separately-trained models, with the same hyperparameters as much as possible. Then, we compare our models against state-of-the-art techniques. See also the appendices for more details, visualizations and discussions.
Local features. As an ablation, we evaluate our local features by matching image pairs. We select 200k pairs, each composed of a test and a train image from GLD, where in 1k pairs both images depict the same landmark, and in 199k pairs the two images depict different landmarks. We compute average precision (AP) after ranking the pairs based on the number of inliers. All variants for this experiment use τ equals to the 75th percentile attention score in the last iteration of training. Results are presented in Tab. 1.
首先,我们进行了烧蚀实验,将联合模型产生的特征与单独训练的特征进行比较,并讨论了控制梯度传播的效果。为了公平的比较,我们联合训练的特征是针对等价的单独训练的模型进行评估的,并且尽可能使用相同的超参数。然后,我们将我们的模型与最先进的技术进行比较。请参见附录以获得更多细节、可视化和讨论。
本地特征。作为一种消融,我们通过匹配图像对来评估局部特征。我们选择了200k对图像,每对图像由GLD的一张测试图像和一张火车图像组成,其中1k对图像描绘了相同的地标,而199k对图像描绘了不同的地标。我们计算平均精度(AP)后,排序对的基础上的数量。本实验的所有变量使用τ等于最后一次训练中第75百分位注意力得分。结果见表1。
First, we train solely the attention and dimensionality reduction modules, for 500k iterations, all methods initialized with the same weights from a separately-trained global feature model. These results are marked as not being jointly trained. It can be seen thatour AE outperforms PCA and a simpler method using only a single fully-connected (FC) layer. Performance improves for the AE as λ increases from 0 to 10, decreasing with 20. Then, we jointly train the unified model; in this case, the variant that does not stop gradients to the backbone suffers a large drop in performance, while the variant that stops gradients obtains similar results as in the separately-trained case.
首先,我们单独训练关注和降维模块,在50万次迭代中,所有方法都使用单独训练的全局特征模型的相同权重初始化。这些结果被标记为没有联合训练。可以看出,我们的AE优于PCA和仅使用单个全连接(FC)层的更简单的方法。当λ从0增加到10时,声发射性能提高,当λ增加到20时,声发射性能降低。然后,我们共同训练统一模型;在这种情况下,不停止向主干梯度的变体的性能会大幅下降,而停止梯度的变体得到的结果与单独训练的情况类似。
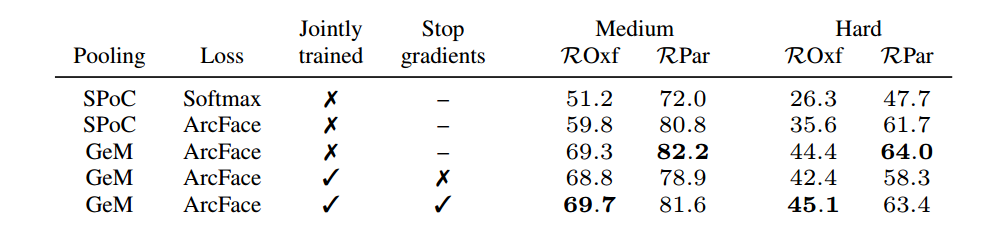
Table 2: Global feature ablation. Comparison of global features, trained separately or jointly, with different pooling methods (SPoC, GeM) and loss functions (Softmax, ArcFace). We report mean average precision (mAP %) on the ROxf and RPar datasets.
表2:全局特征消融。使用不同池化方法(SPoC, GeM)和损失函数(Softmax, ArcFace)单独或联合训练的全局特征的比较。我们报告了ROxf和RPar数据集的平均精度(mAP %)。
The poor performance of the naive jointly trained model is due to the degradation of the hierarchical feature representation. This can be assessed by observing the evolution of activation sparsity in S (conv4) and D (conv5), as shown in Fig. 3. Generally, layers representing more abstract and high-level semantic properties (usually deeper layers) have high levels of sparsity, while shallower layers representing low-level and more localizable patterns are dense. As a reference, the ImageNet pre-trained model presents on average 45% and 82% sparsity for these two feature maps, respectively, when run over GLD images. For the naive joint training case, the activations of both layers quickly become much sparser, reaching 80% and 97% at the end of training; in comparison, our proposed training scheme preserves similar sparsity as the ImageNet model: 45% and 88%. This suggests that the conv4 features in the naive case degrade for the purposes of local feature matching; controlling the gradient effectively resolves this issue
朴素联合训练模型性能差的原因是层次特征表示的退化。这可以通过观察S (conv4)和D (conv5)的激活稀疏度演变来评估,如图3所示。通常,表示更抽象和高级语义属性的层(通常是更深的层)具有高度的稀疏性,而表示低级和更可本地化模式的较浅层则是密集的。作为参考,当在GLD图像上运行时,ImageNet预训练模型对这两个特征映射的平均稀疏度分别为45%和82%。对于朴素联合训练案例,两层的激活度很快变得稀疏,在训练结束时分别达到80%和97%;相比之下,我们提出的训练方案与ImageNet模型保持相似的稀疏度:45%和88%。这表明朴素情况下的conv4特征为了局部特征匹配而降级;控制梯度有效地解决了这个问题
Global features. Tab. 2 compares global feature training methods. The first three rows present global features trained with different loss and pooling techniques. We experiment with standard Softmax Cross-Entropy and ArcFace losses; for pooling, we consider standard average pooling (equivalent to SPoC) and GeM. ArcFace brings an improvement of up to 14%, and GeM of up to 9:5%. GeM pooling and ArcFace loss are adopted in our final model. Naively training a joint model, without controlling gradients, underperforms when compared to the baseline separately-trained global feature, with mAP decrease of up to 5:7%. Once gradient stopping is employed, the performance can be recovered to be on par with the separately-trained version (a little better on ROxf, a little worse on RPar). This is expected, since the global feature in this case is optimized by itself, without influence from the local feature head.
全局特征。表2比较了全局特征训练方法。前三行表示用不同损失和池化技术训练的全局特征。我们用标准的Softmax交叉熵和ArcFace损失进行实验;对于池化,我们考虑标准平均池化(相当于SPoC)和GeM。ArcFace带来了高达14%的改进,GeM高达9:5%。我们最终的模型采用GeM池和ArcFace loss。在不控制梯度的情况下,单纯训练联合模型与单独训练的基线全局特征相比表现不佳,mAP下降高达5:7%。一旦使用梯度停止,性能可以恢复到与单独训练的版本相当(在ROxf上稍微好一点,在RPar上稍微差一点)。这是意料之中的,因为在这种情况下,全局特征是自己优化的,不受局部特征头的影响。
Comparison to retrieval state-of-the-art. Tab. 3 compares our model against the retrieval state-of-the-art. Three settings are presented: (A) local feature aggregation and re-ranking (previous work); (B) global feature similarity search; (C) global feature search followed by re-ranking with local feature matching and spatial verification (SP).
In setting (B), the DELG global feature variants strongly outperform previous work for all cases (most noticeably in the large-scale setting): 7:1% absolute improvement in ROxf+1M-Hard and 7:5% in RPar+1M-Hard. Note that we obtain strong improvement seven when using the ResNet-50 backbone, while the previous state-of-the-art used
ResNet-101/152, which are much more complex (2X/3X the number of floating point operations, respectively). To ensure a fair comparison, we present results from which specifically use the same training set as ours, marked as “(GLD)” – the results are obtained from the authors’ official codebases. In particular, note that “R152-GeM (GLD)” uses not only the same training set, but also the same exact scales in the image pyramid; even if our method is much cheaper, it consistently outperforms others.
检索技术对比。表3将我们的模型与检索技术进行了比较。提出了三种设置:(A)局部特征聚合和重新排序(以前的工作);(B)全局特征相似度搜索;(C)全局特征搜索,再通过局部特征匹配和空间验证(SP)重新排序。
在设置(B)中,DELG全局特征变体在所有情况下(最明显的是在大规模设置中)都明显优于以前的工作:ROxf+1M-Hard的绝对改进为7:1%,RPar+1M-Hard的绝对改进为7:5%。请注意,当使用ResNet-50骨干网时,我们获得了强大的改进7,而之前使用的是最先进的技术
ResNet-101/152,它们要复杂得多(分别是浮点运算次数的2X/3X)。为了确保公平的比较,我们给出了使用与我们相同的训练集的结果,标记为“(GLD)”——结果来自作者的官方代码库。特别要注意的是,“R152-GeM (GLD)”不仅使用相同的训练集,而且在图像金字塔中也使用相同的精确尺度;即使我们的方法便宜得多,它也始终优于其他方法。
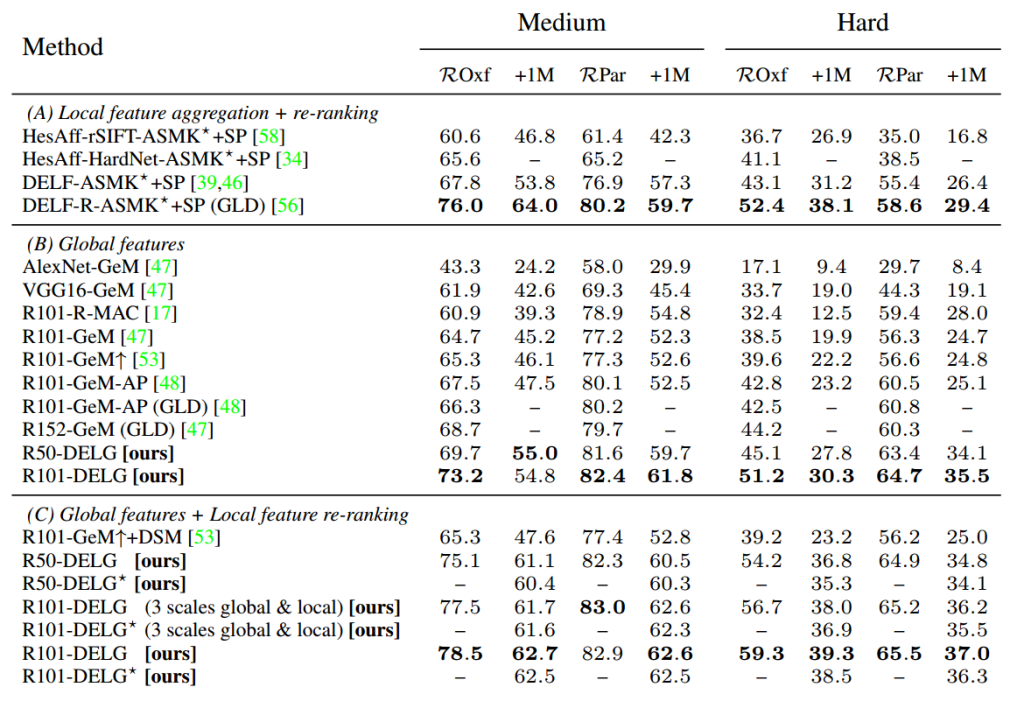
表3:与检索状态的比较。在ROxf/RPar数据集(及其大规模版本ROxf+1M/RPar+1M)上使用中评估协议和硬评估协议的结果(% mAP)。最上面的一组行(A)显示了使用局部特征聚合和重新排序的先前工作的结果。其他行集仅使用(B)全局特征呈现结果,或(C)初始搜索的全局特征,然后使用局部特征重新排序。DELG吗?是DELG的一个版本,其中局部特征是二值化的。DELG和DELG?大大优于之前在装置(B)和(C)中的工作。DELG在8个病例中有7个优于设置(A)的方法。
even when using the ResNet-50 backbone, while the previous state-of-the-art used ResNet-101/152, which are much more complex (2X/3X the number of floating point operations, respectively). To ensure a fair comparison, we present results from [47,48] which specifically use the same training set as ours, marked as “(GLD)” – the results are obtained from the authors’ official codebases. In particular, note that “R152-GeM (GLD) [47]” uses not only the same training set, but also the same exact scales in the image pyramid; even if our method is much cheaper, it consistently outperforms others.
For setup (C), we use both global and local features. For large-scale databases, it may be impractical to store all raw local features in memory; to alleviate such requirement, we also present a variant, DELG? , where we store local features in binarized format, by simply applying an elementwise function: b(x) = +1 if x > 0; −1 otherwise.
即使在使用ResNet-50骨干网时,而以前最先进的技术使用的是ResNet-101/152,它们要复杂得多(分别是浮点运算次数的2倍/3倍)。为了确保公平的比较,我们给出了[47,48]中的结果,它们特别使用了与我们相同的训练集,标记为“(GLD)”——结果来自作者的官方代码库。特别要注意的是,“R152-GeM (GLD)[47]”不仅使用了相同的训练集,而且在图像金字塔中也使用了相同的精确尺度;即使我们的方法便宜得多,它也始终优于其他方法。
对于设置(C),我们同时使用全局和局部特征。对于大型数据库,将所有原始的本地特征存储在内存中可能是不切实际的;为了缓解这种需求,我们还提出了一个变体DELG?,其中我们通过简单地应用一个元素函数以二值化格式存储局部特征:如果x > 0,则b(x) = +1;−1。
Local feature re-ranking boosts performance substantially for DELG, compared to only searching with global features, especially in large-scale cases: gains of up to 9% (in ROxf+1M-Hard). We also present results where local feature extraction is performed with 3 scales only, the same ones used for global features. The large-scale results are similar, providing a boost of up to 7:7%. Results for DELG? also provide large improvements, but with performance that is slightly lower than the corresponding unbinarized versions. Our retrieval results also outperform DSM significantly, by more than 10% in several cases. Different from our proposed technique, the gain from spatial verification reported in their work is small, of at most 1:5% absolute. DELG also outperforms local feature aggregation results from setup (A) in 7 out of 8 cases,establishing a new state-of-the-art across the board.
与只搜索全局特征相比,局部特征重新排序大大提高了DELG的性能,特别是在大规模情况下:增益高达9%(在ROxf+1M-Hard中)。我们还展示了仅用3个尺度进行局部特征提取的结果,与用于全局特征的结果相同。大规模的结果是相似的,提供了高达7:7%的提升。DELG的结果?也提供了很大的改进,但性能略低于相应的未二进制化版本。我们的检索结果也明显优于DSM,在一些情况下超过10%。与我们提出的技术不同,在他们的工作中报告的空间验证的增益很小,绝对值最多为1:5%。DELG在8种情况中的7种情况下也优于来自设置(A)的局部特征聚合结果,从而全面建立了一种新的状态。
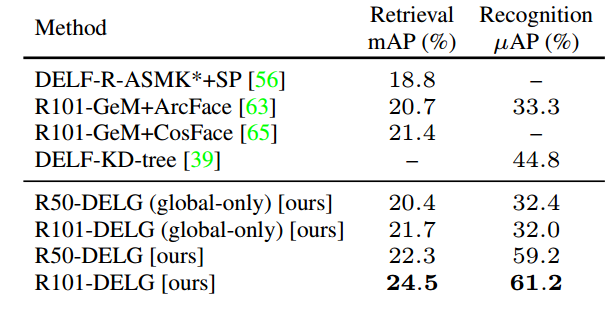
表4:GLDv2评估。在GLDv2数据集上的结果,对于检索和识别任务,关于查询集的“测试”分割。为了公平比较,所有方法都是在GLD上进行训练的。
Comparison of DELG against other recent local features; results (% mAP) on the ROxf dataset.
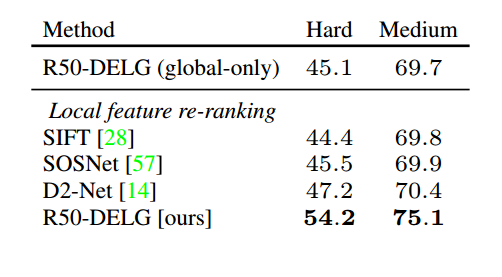
表5:重新排序实验。
DELG与其他近期本地特征的比较;ROxf数据集上的结果(% mAP)。
GLDv2 evaluation. Tab. 4 compares DELG against previous GLDv2 results, where for a fair comparison we report methods trained on GLD. DELG achieves top performance in both retrieval and recognition tasks, with local feature re-ranking providing a significant boost in both cases – especially on the recognition task (29:2% absolute improvement). Note that recent work has reported even higher performance on the retrieval task, by learning on GLDv2’s training set and using query expansion techniques / ensembling. On the other hand, DELG’s performance on the recognition task is so far the best reported single-model result, outperforming many ensemble-based methods (by itself, it would have been ranked top-3 in the 2019 challenge) .
GLDv2评估。表4将DELG与以前的GLDv2结果进行了比较,为了公平比较,我们报告了在GLD上训练的方法。DELG在检索和识别任务中都达到了最高的性能,局部特征重新排序在这两种情况下都提供了显著的提升——尤其是在识别任务上(29.2%的绝对改进)。请注意,通过学习GLDv2的训练集和使用查询扩展技术/集成,最近的工作报告了更高的检索任务性能。另一方面,DELG在识别任务上的表现是迄今为止报道的最佳单模型结果,优于许多基于集成的方法(就其本身而言,它将在2019年的挑战中排名前三)。
Re-ranking experiment. Tab. 5 further compares local features for re-ranking purposes. R50-DELG is compared against SIFT, SOSNet (HPatches model, DoG keypoints) and D2-Net (trained, multiscale). All methods are given the same retrieval short list of 100 images for re-ranking (based on R50-DELG-global retrieval); for a fair comparison, all methods use 1k features and 1k RANSAC iterations. We tuned matching parameters separately for each method: whether to use ratio test or distance threshold for selecting correspondences (and their associated thresholds); RANSAC residual threshold; minimum number of inliers (below which we declare no match).
SIFT and SOSNet provide little improvement over the global feature, due to suboptimal feature detection based on our observation (i.e., any blob-like feature is detected, which may not correspond to landmarks). D2-Net improves over the global feature, benefiting from a better feature detector. DELG outperforms other methods by a large margin.
评估实验。表5进一步比较了本地特征,以便重新排序。将R50-DELG与SIFT、SOSNet (HPatches模型、DoG关键点)和D2-Net(训练的、多尺度的)进行比较。所有方法都给出相同的100张图像检索短列表进行重新排序(基于r50 - delg -全局检索);为了公平比较,所有方法都使用1k个特征和1k个RANSAC迭代。我们分别为每种方法调整匹配参数:是否使用比率测试或距离阈值来选择对应(及其相关阈值);RANSAC残差阈值;最小内层数(以下声明不匹配)。
SIFT和SOSNet对全局特征的改进很小,这是由于基于我们的观察的次优特征检测(即,检测到的任何blob-like特征可能不对应于地标)。D2-Net改进了全局特征,受益于更好的特征检测器。DELG的性能大大优于其他方法。
Latency and memory. Tab. 6 reports feature extraction latency and index memory footprint for state-of-the-art methods, corresponding to the three settings from Tab. 3; as a reference, we also present numbers for DELF (which uses an R50 backbone). Joint extraction with DELG allows for substantial speed-up, compared to running two separate local and global models: when using 3 local feature scales, separately running R50-GeM and DELF would lead to 198ms, while the unified model runs with latency of 118ms(40% faster). For the R50 case with 7 local scales, the unified model is 30% faster. The binarization technique adds negligible overhead, having roughly the same latency.
延迟和内存。表6报告了最先进方法的特征提取延迟和索引内存占用,对应于表3中的三种设置;作为参考,我们还提供了DELF(使用R50主干)的数字。与运行两个单独的局部和全局模型相比,DELG联合提取允许大幅加速:当使用3个局部特征尺度时,分别运行R50-GeM和DELF将导致198ms,而统一模型运行延迟为118ms(快40%)。对于有7个局部尺度的R50案例,统一模型的速度快了30%。二值化技术增加的开销可以忽略不计,并且具有大致相同的延迟。
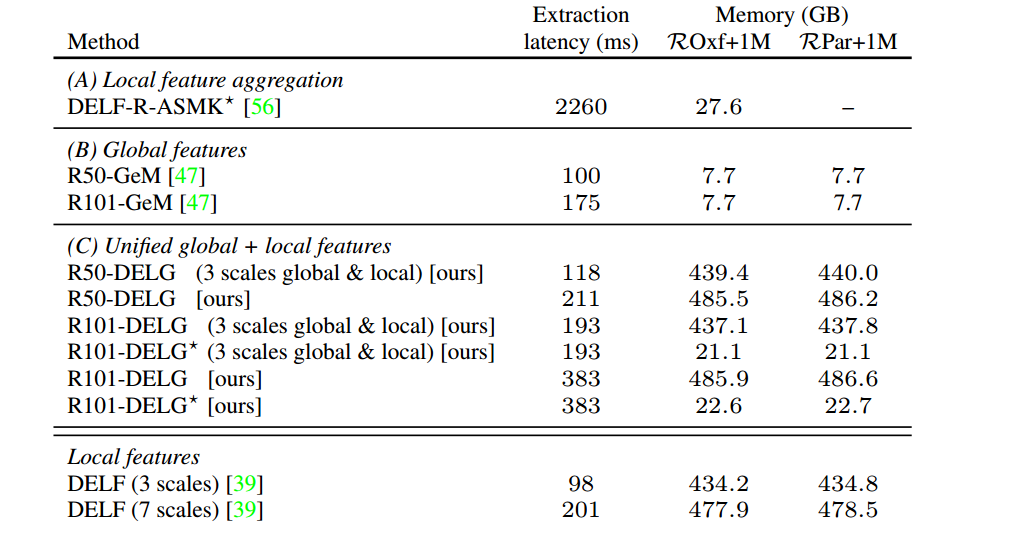
表6:不同图像检索模型的特征提取延迟和数据库内存需求。延迟是在NVIDIA Tesla P100 GPU上测量的,对于1024边的正方形图像。(一)DELF-R-ASMK ?测量使用的代码和默认配置来自;(B) ResNet-GeM变体使用3种图像尺度;(C) DELG和DELG?在不同的配置下进行比较。作为参考,我们还在最后一行中提供了DELF的数字。
Storing unquantized DELG local features requires excessive index memory requirements; using binarization, this can be reduced significantly: R101-DELG? requires 23GB. This is lower than the memory footprint of DELF-R-ASMK? . Note also that feature extraction for DELG? is much faster than for DELF-R-ASMK? , by more than 5×.
R50-DELG with 3 scales is also faster than using a heavier global feature (R101-GeM), besides being more accurate. As a matter of fact, several of the recently-proposed global features use image pyramids with 3 scales; our results indicate that their performance can be improved substantially by adding a local feature head, with small increase in extraction latency, and without degrading the global feature.
存储非量化DELG局部特征需要过多的索引内存需求;使用二值化,这可以显著减少:需要23 gb。这比DELF-R-ASMK?. 还要注意DELG的特征提取?比DELF-R-ASMK快得多?,降幅超过5倍。
带有3个刻度的R50-DELG也比使用更重的全局特征(R101-GeM)更快,而且更准确。事实上,最近提出的一些全局特征使用3个尺度的图像金字塔;我们的结果表明,通过添加一个局部特征头,它们的性能可以得到很大的提高,提取延迟的增加很小,并且不会降低全局特征。
Comparison against concurrent work. Our global feature outperforms the SOLAR global feature method for all datasets and evaluation protocols, with gains of up to 3:3%. Compared to Tolias et al, we obtain similar results on ROxf/RPar; for the large-scale setting, their best average mAP across the two datasets is 50:1%, while R101-DELG obtains 50:4% and R101-DELG? obtains 50:0% (in general, our method is a little better on RPar and theirs on ROxf). On GLDv2-recognition, Tolias et al achieve 36:5% µAP, while R101-DELG obtains 61:2%.
与并发工作的比较。我们的全局特征在所有数据集和评估协议中都优于SOLAR全局特征方法,增益高达3:3%。与Tolias等人相比,我们在ROxf/RPar上得到了类似的结果;在大尺度条件下,两组数据集的最佳平均mAP值为50:1%,而R101-DELG的平均mAP值为50:4%,R101-DELG?获得50:0%(一般来说,我们的方法在RPar上略好于他们的方法在ROxf上)。在gldv2识别上,Tolias等实现了36:5%的µAP,而R101-DELG实现了61:2%。
Qualitative results. We give examples of retrieval results, to showcase the DELG model. Fig. 4a illustrates difficult cases, where the database image shows a very different viewpoint, or significant lighting changes; these images can still achieve relatively high ranks due to effective global features, which capture well the similarity even in such challenging scenarios. In these cases, local features do not produce sufficient matches.
定性的结果。我们给出了检索结果的示例,以展示DELG模型。图4a说明了一些困难的情况,其中数据库图像显示了非常不同的视点,或显著的光照变化;由于有效的全局特征,这些图像仍然可以获得相对较高的排名,即使在这样具有挑战性的场景中,它们也能很好地捕捉到相似性。在这些情况下,局部特征不能产生足够的匹配。

图4:ROxf-Hard和RPar-Hard上的DELG示例结果。(a)为10个不同查询检索到的难度高、排名高的相关图像示例。这些检索到的数据库图像经过几何验证(如果有的话),它们的内层数很少,这意味着它们的相似性主要是由全局特征捕获的。(b)使用局部特征说明重新排序阶段的性能改进的例子。对于每个查询(左),右侧显示两行,上面显示基于全局特征相似度的结果,下面显示使用局部特征对前100个图像重新排序后的结果。正确的结果用绿色边框标记,错误的结果用红色边框标记。虽然顶部检索的全局特征结果通常排序不正确,但局部特征匹配可以有效地重新排序以提高精度。
Fig. 4b shows the effect of local feature re-ranking for selected queries, for which substantial gains are obtained. Global features tend to retrieve images that have generally similar appearance, but which sometimes do not depict the same object of interest; this can be improved substantially with local feature re-ranking, which enables stricter matching selectivity. As can be observed in these two figures, global features are crucial for high recall, while local features are key to high precision.
图4b显示了对所选查询进行局部特征重新排序的效果,从中获得了可观的收益。全局特征倾向于检索具有大致相似外观的图像,但有时不描述相同的感兴趣对象;这可以通过局部特征重新排序得到显著改善,从而实现更严格的匹配选择。从这两张图中可以看出,全局特征对于高召回率至关重要,而局部特征对于高精度至关重要。
Conclusions 结论
Our main contribution is a unified model that enables joint extraction of local and global image features, referred to as DELG. The model is based on a ResNet backbone, leveraging generalized mean pooling to produce global features and attention-based keypoint detection to produce local features. We also introduce an effective dimensionality reduction technique that can be integrated into the same model, based on an autoencoder. The entire network can be trained end-to-end using image-level labels and does not require any additional post-processing steps. For best performance, we show that it is crucial to stop gradients from the attention and autoencoder branches into the network backbone, otherwise a suboptimal representation is obtained. We demonstrate the effectiveness of our method with comprehensive experiments, achieving state-of-the-art performance on the Revisited Oxford, Revisited Paris and Google Landmarks v2 datasets.
我们的主要贡献是一个统一的模型,可以联合提取局部和全局图像特征,称为DELG。该模型基于ResNet主干,利用广义均值池生成全局特征,利用基于注意力的关键点检测生成局部特征。我们还介绍了一种有效的降维技术,该技术可以基于自动编码器集成到同一模型中。整个网络可以使用图像级标签进行端到端的训练,并且不需要任何额外的后处理步骤。为了获得最佳性能,我们表明阻止注意力和自编码器分支向网络主干的梯度是至关重要的,否则将获得次优表示。我们通过全面的实验证明了我们方法的有效性,在Revisited Oxford, Revisited Paris和Google Landmarks v2数据集上实现了最先进的性能。
Comments NOTHING